在不久之前公布的 ICCV 2021 论文奖项中,来自微软亚洲研究院的研究者凭借论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》斩获 ICCV 2021 马尔奖(最佳论文)。这篇论文的作者主要包括中国科学技术大学的刘泽、西安交通大学的林宇桐、微软的曹越和胡瀚等人。该研究提出了一种新的 vision Transformer,即 Swin Transformer,它可以作为计算机视觉的通用骨干。
相比之前的 ViT 模型,Swin Transformer 做出了以下两点改进:其一,引入 CNN 中常用的层次化构建方式构建分层 Transformer;其二,引入局部性(locality)思想,对无重合的窗口区域内进行自注意力计算。在 Swin Transformer 论文公开没多久之后,微软官方也在 GitHub 上开源了代码和预训练模型,涵盖图像分类、目标检测以及语义分割任务。
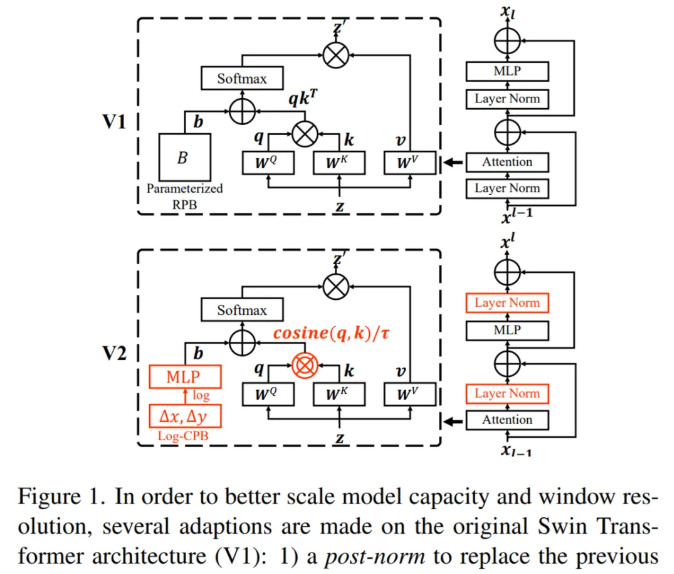
近日,该团队又提出一种升级版 SwinTransformer V2。
为了解决上述问题,该团队将 SwinTransformer 作为基线提出了几种改进技术,具体表现在:
此外,该研究还介绍了关键实现细节,这些细节可显着节省 GPU 内存消耗,使得常规 GPU 训练大型视觉模型成为可能。使用这些技术和自监督预训练,该团队训练了一个具有 30 亿参数的 Swin Transformer 模型,并将其有效地迁移到高分辨率图像或窗口的各种视觉任务中,在各种基准上实现了 SOTA 性能。
通过扩展容量和分辨率,Swin Transformer V2 在四个具有代表性的基准上刷新纪录:在 ImageNet-V2 图像分类任务上 top-1 准确率为 84.0%,COCO 目标检测任务为 63.1 / 54.4 box / mask mAP,ADE20K 语义分割为 59.9 mIoU,Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢