

本篇文章来自2021年10月发表在Journal of Chemical Information And Modeling上的MolGPT: Molecular Generation Using a Transformer-Decoder Model。文章提出了一个来预测分子生成的SMILES标记序列。该模型利用了掩蔽的自我注意机制,使学习字符串标记之间的长期依赖关系变得更简单。这对于学习满足配价和环闭包的有效字符串的语义特别有用。此外,该模型通过分子性质控制学习更高层次的化学表示。MolGPT能够生成属性值与用户传递的精确值仅略有偏差的分子。它还能够生成包含用户指定骨架的分子,同时控制这些特性。
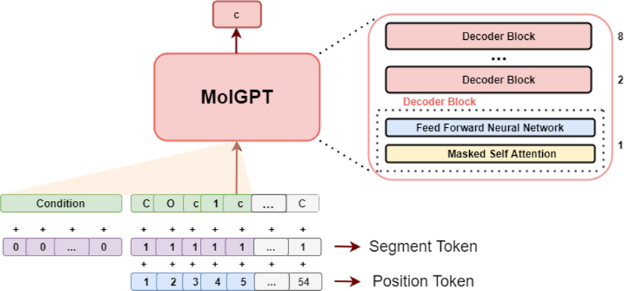
MolGPT模型结构
MolGPT由堆叠的解码块组成,每个解码块由屏蔽的自我注意层和完全连接的神经网络组成。完全连接的神经网络的最后一层返回一个大小为256的向量,然后用作下一个解码器块的输入。MolGPT由八个这样的解码器块组成。为了跟踪输入序列的顺序,将位置值嵌入分配给每个标记。在条件训练期间,提供段标记以区分条件和SMILES标记。段标记嵌入表示特定输入是一种条件还是一种分子标记,以便于模型区分两者。使用嵌入层将所有分子标记映射到256维向量。类似地,使用单独的可训练嵌入层将位置标记和分段标记映射到256维向量。然后添加这些SMILES标记嵌入、位置嵌入和段标记嵌入,从而为SMILES字符串的每个标记生成大小为256的向量,然后将其作为输入传递给模型。
论文链接:
https://pubs.acs.org/doi/abs/10.1021/acs.jcim.1c00600
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢