
目标检测是一项基本的计算机视觉任务,其目的是识别图像中的目标实例,并使用精确的边界框对其进行定位。现代检测器主要利用代理学习目标(proxy learning objectives)来处理该集合预测任务,即,回归距预定义锚框的偏移量或距网格位置的边界。这些启发式设计不仅使模型设计复杂化,而且还需要手工制作的后处理来消除重复。
最近的一种方法DETR消除了这些手工设计,实现了端到端的目标检测。它在卷积特征图上建立了一个有效的集合预测框架,并显示出与faster R-CNN检测器相当的性能。特征图在空间维度上被展平为一维特征向量。然后,transformer利用其强大的注意机制对它们进行处理,以生成最终的检测列表。
尽管简单而有效,但将transformer网络应用于图像特征映射可能在计算上代价高昂,这主要是由于对长展平的特征向量的注意操作。这些特征可能是冗余的:除了感兴趣的对象之外,自然图像通常包含巨大的背景区域,这些背景区域可能在相应的特征表示中占据很大一部分;而且,一些区分特征向量可能已经足以检测对象。现有的提高transformer效率的工作主要集中在加速注意操作上,很少考虑上面讨论的空间冗余。

论文链接:https://arxiv.org/abs/2109.07036
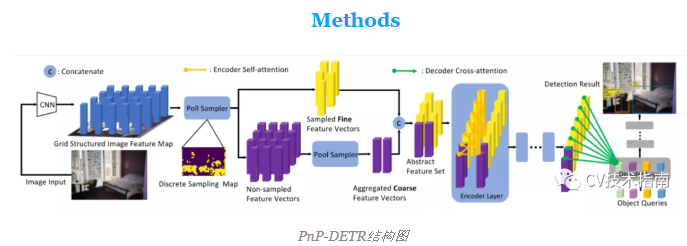
为了解决上述局限性,论文开发了一个可学习的轮询和池化(Poll and Pool, PnP)采样模块。它的目的是将图像特征图压缩成由精细特征向量和少量粗略特征向量组成的抽象特征集。
从输入特征图中确定性地采样精细特征向量,以捕捉精细前景信息,这对于检测目标是至关重要的。粗略特征向量聚合来自背景位置的信息,所产生的上下文信息有助于更好地识别和定位对象。然后,transformer对细粗特征空间内的信息交互进行建模,并获得最终结果。
由于抽象集比直接扁平化的图像特征图短得多,因此transformer的计算量大大减少,并且主要分布在前景位置。这种方法与提高transformer效率的方法是正交的,可以进一步与它们结合得到更有效的模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢