标题:微软|Swin Transformer V2: Scaling Up Capacity and Resolution(Swin Transformer V2:扩大容量和分辨率)
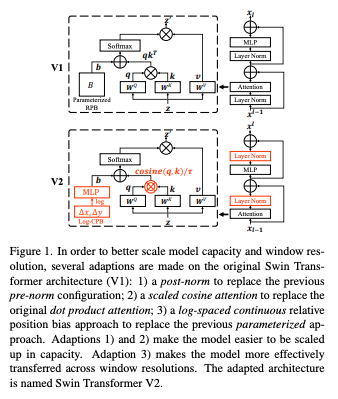
简介:本文提出一种图像应用的预训练技术。作者提出了缩放Swin Transformer的技术,能够训练多达30亿个参数并使其图像分辨率高达1,536×1,536。通过扩大规模容量和分辨率,Swin Transformer在四个代表性视觉基准上创下新记录:在ImageNet-V2图像分类上的84.0%top-1准确率,COCO对象检测上的box/ mask63.1/54.4mAP,ADE20K语义分割59.9mIoU,Kinetics-400视频动作分类86.8%的top-1准确率。作者提出了几种技术,它们是通过使用Swin Transformer作为案例研究来说明:1)后归一化技术和缩放余弦注意方法,以提高大型视觉模型的稳定性; 2) 对数间隔连续位置偏置技术有效地将在低分辨率图像和窗口中预先训练的模型传输到更高分辨率的对应模型。使用这些技术和自我监督的预训练,作者成功地训练了一个强大的30亿Swin Transformer模型并有效传递到涉及高分辨率图像的各种视觉任务,在各项基准测试中达到最先进的精度。
代码下载:https://github.com/microsoft/Swin-Transformer
论文地址:https://arxiv.org/pdf/2111.09883v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢