
本文介绍一篇KDD2021年的文章:《An Embedding Learning Framework for Numerical Features in CTR Prediction》。该文章介绍了一种对连续特征进行embedding的方法:AutoDis。该方法具有以下三种优点:1. 高模型容量。2. 端到端训练。3. 连续特征embedding具有唯一的表示。
论文链接:
https://arxiv.org/abs/2012.08986
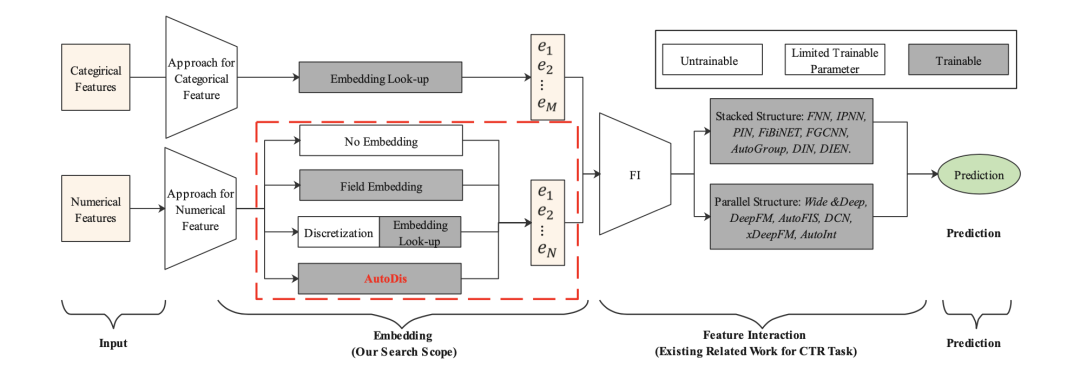 图1. CTR预估的Embedding & Feature Interaction 架构。
图1. CTR预估的Embedding & Feature Interaction 架构。
如图1所示,目前大多数的CTR预估方法遵循Embedding&Feature Interaction架构。由于CTR预估任务中特征交叉(Feature Interaction)的重要性,目前大多数的工作围绕着研究特征交叉的方法。然而Embedding的方式也同样重要。有以下两点原因:
- Embedding模块是特征交叉的基础。
- Embedding模块的参数量最多,对预测结果有着深远的影响。
如图1.所示,对于类别型特征(Categirical Features),由于类别型特征取值有限,一般采用查表(look-up)的方式来进行embedding。然而对于连续(数值)型特征,由于其无限的取值,缺少一种十分有效的embedding方法。如图1所示:目前的连续型特征embedding方法主要为以下三种:
- No embedding: 直接使用其原始值输入DNN来进行embedding。
- Field Embedding:为每个连续特征域单独学习一个embedding向量,然后用原始值与embedding向量相乘。
- 离散化:将连续(数值)型特征进行离散化分桶,然后采用类别型特征的embedding方法(查表(look-up))。
然而,前两种方法的表示容量较低(low capacity of representations),可能会导致次优结果。最后一种方法会存在SBD (Similar value But Dis-similar embedding) 和 DBS (Dis-similar value But Same embedding)问题。
为了解决上述问题,该文章提出了AutoDis方法。在AutoDis方法中,首先为每个连续特征域设计一个 meta-embeddings来学习全局共享的知识;接着,设计了可导自动离散化过程,捕捉连续型特征与meta-embeddings的关系,最后采用一种聚合方法来为每个特征学习一种连续但不同且唯一的embedding。
AutoDis由:Meta-Embeddings,Automatic Discretization,以及Aggregation Function组成。AutoDis的大致流程如下:
-
首先,AutoDis为每一个领域(field)的连续型特征定义了一组Meta-Embeddings。
-
接着,AutoDis自动(可学习)对每个领域的特征值进行离散化,并将其分配到不同的Meta-Embeddings桶中(每个领域的特征值可能分到一个桶中也可能多个桶)。
-
最后采用一种聚合方法,将多个桶的embedding结果聚合,得到最后连续特征值的embedding。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢