
作者:Linlin Liu, Xin Li, Ruidan He,等
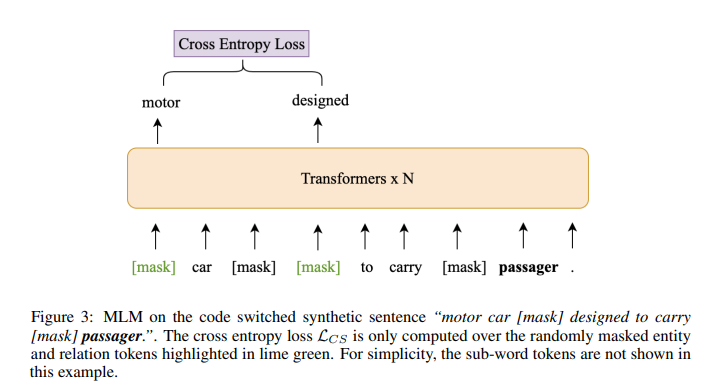
简介:本文研究基于知识的多语言预训练模型。知识丰富的语言表示学习,在各种知识密集型 NLP 任务中表现出良好的性能。然而,现有的基于知识的语言模型都是用单语知识图数据训练的,这限制了它们对更多语言的应用。在这项工作中,作者提出了一个新颖的框架来预训练基于知识的多语言模型(KMLM)。作者首先使用维基数据知识图生成大量代码切换合成句子和基于推理的多语言训练数据。然后基于生成数据的句内和句间结构,作者设计了预训练任务以促进知识学习,这使得语言模型不仅可以记住事实知识,还可以学习有用的逻辑模式。作者预训练的 KMLM 在广泛的知识密集型跨语言 NLP 任务上表现出显着的性能提升,包括命名实体识别、事实知识检索、关系分类以及作者设计的一项新任务,即逻辑推理。作者的代码和预训练语言模型将公开发布。
论文下载:https://arxiv.org/pdf/2111.10962.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢