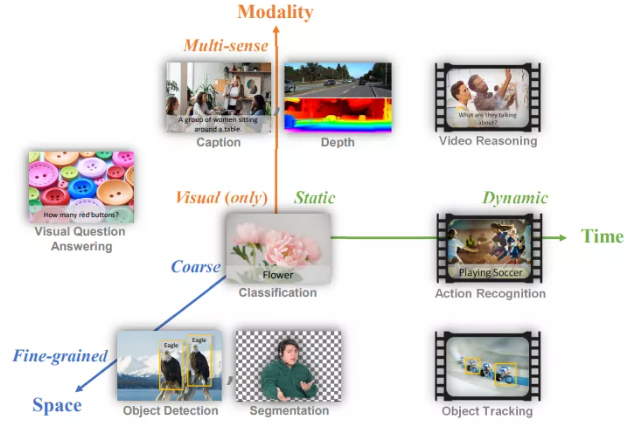
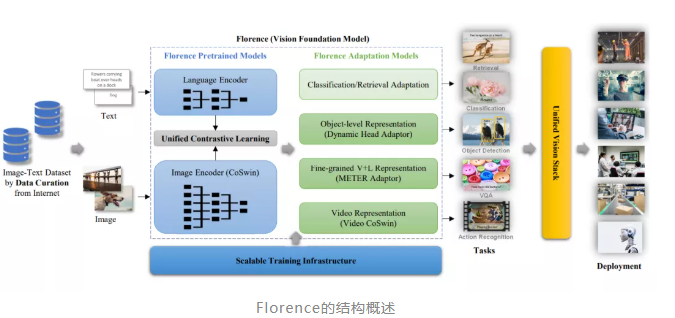
近日,微软正式发布了一个新的计算机视觉基础模型Florence(佛罗伦萨),要用一个模型一统多模态天下!Florence可以轻松适用于各种计算机视觉任务,如分类、目标检测、VQA、看图说话、视频检索和动作识别,并在超过40个基准中刷新了SOTA。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

近日,微软正式发布了一个新的计算机视觉基础模型Florence(佛罗伦萨),要用一个模型一统多模态天下!Florence可以轻松适用于各种计算机视觉任务,如分类、目标检测、VQA、看图说话、视频检索和动作识别,并在超过40个基准中刷新了SOTA。
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢