
随着网络上各种信息的指数级增长,以及跨语言获取信息的需求不断增加,机器翻译逐渐成为网上冲浪🏄♀️时必不可少的工具。网页翻译让我们在 Reddit 等外国论坛里和网友谈笑风生;火山同传等智能字幕翻译系统让我们无需等待字幕组,直接观看“生肉”剧集;聊天翻译让我们建立跨国贸易,结交外国友人。
然而,上面提到的场景往往有一个共同点,那就是被翻译的文本往往是不规范的。无论是聊天时手误导致的错别字,还是视频语音原文识别的错误,都会极大地影响译文质量。因此,实际应用场景下的机器翻译对翻译模型的鲁棒性有很高的要求。
今天就为大家介绍一篇由字节跳动人工智能实验室火山翻译团队发表在 EMNLP 2021 Findings 的短文 - Secoco: Self-Correcting Encoding for Neural Machine Translation。这篇论文让翻译模型在学习翻译任务的同时,学习如何对输入的带噪文本进行纠错,从而改善翻译质量。

论文地址:https://arxiv.org/abs/2108.12137
代码地址:https://github.com/rgwt123/Secoco
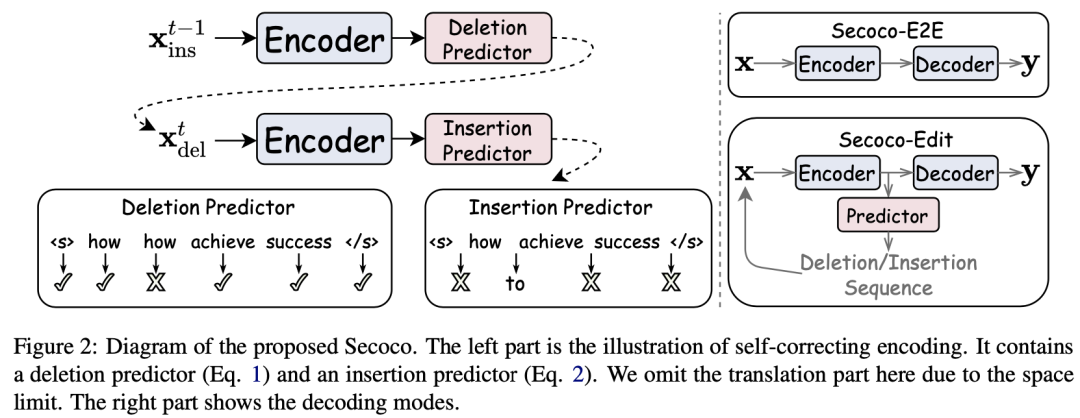 整体模型架构
整体模型架构
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢