
论文标题: PTQ4ViT: Post-Training Quantization Framework for Vision Transformers
论文链接:https://arxiv.org/abs/2111.12293
代码链接:https://github.com/hahnyuan/PTQ4ViT
作者单位:北京大学 & Houmo AI
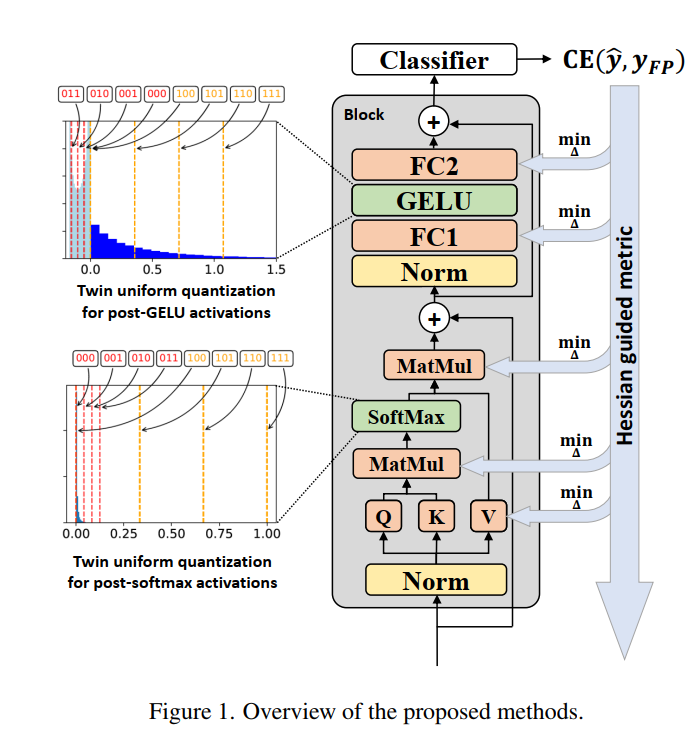
量化是压缩神经网络最有效的方法之一,在卷积神经网络(CNN)上取得了巨大的成功。最近,视觉Transformer在计算机视觉中展现了巨大的潜力。然而,之前的训练后量化方法在视觉变换器上表现不佳,导致即使在 8 位量化中精度下降超过 1%。因此,我们分析了视觉Transformer上的量化问题。我们观察到 softmax 和 GELU 函数后激活值的分布与高斯分布有很大不同。我们还观察到常见的量化指标,例如 MSE 和余弦距离,无法准确确定最佳缩放因子。在本文中,我们提出了孪生均匀量化方法来减少这些激活值的量化误差。我们建议使用 Hessian 引导度量来评估不同的缩放因子,从而以较小的成本提高校准的准确性。为了实现视觉转换器的快速量化,我们开发了一个高效的框架 PTQ4ViT。实验表明,量化的视觉转换器在 ImageNet 分类任务上实现了接近无损的预测精度(8 位量化时下降小于 0.5%)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢