
大规模的视觉和语言表征学习在各种视觉语言任务上显示出了良好的提升。现有的方法大多采用基于Transformer的多模态编码器来联合建模视觉token和单词token。由于视觉token和单词token不对齐,因此多模态编码器学习图像-文本交互具有挑战性。
在本文中,作者引入了一种对比损失,通过在跨模态注意前融合(ALBEF)来调整图像和文本表示,从而引导视觉和语言表示学习 。与大多数现有的方法不同,本文的方法不需要边界框标注或高分辨率的图像。为了改进从噪声web数据中学习,作者提出了动量蒸馏,这是一种从动量模型产生的伪目标中学习的自训练方法。
作者从互信息最大化的角度对ALBEF进行了理论分析,表明不同的训练任务可以被解释为图像-文本对生成视图的不同方式。ALBEF在多个下游的语言任务上实现了SOTA的性能。在图像-文本检索方面,ALBEF优于在相同数量级的数据集上预训练的方法。在VQA和NLVR2上,ALBEF与SOTA的技术相比,实现了2.37%和3.84%的绝对性能提升,同时推理速度更快。

论文链接:
https://arxiv.org/abs/2107.07651
代码:
https://github.com/salesforce/ALBEF
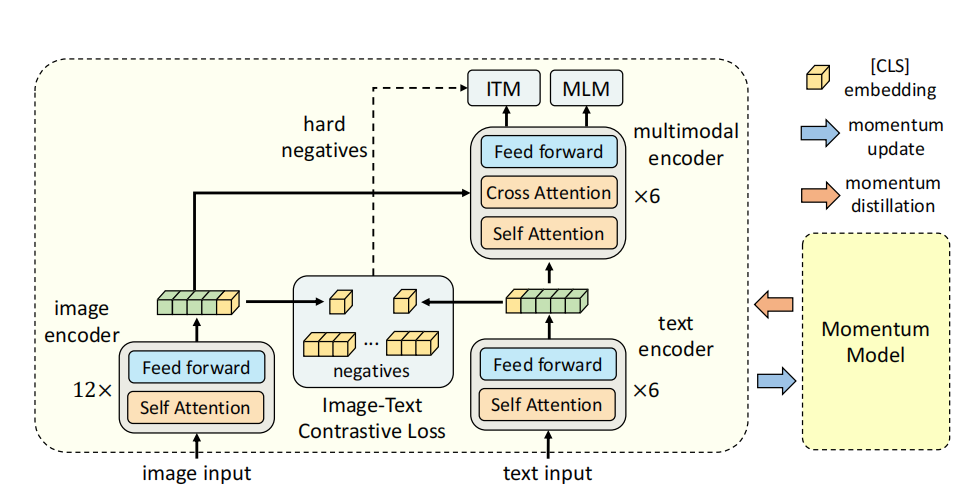
如上图所示,ALBEF包含一个图像编码器、一个文本编码器和一个多模态编码器。作者使用一个12层的视觉Transformer ViT-B/16作为图像编码器,并使用在ImageNet-1k上预训练的权重来初始化它。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢