
本文针对ViT的轻量化研究创新性的提出Transformer as Convolutions,糅合CNN与ViT优势,又弃其糟粕。同时在论文中作者还对MobileViT的移动设备应用(如iPhone)以及不同视觉任务应用(如图像分类、目标检测、语义分割)进行了实验研究,对于训练方法作者采用多尺度采样训练,并使用通用化实验说明其有效性。

论文地址:https://arxiv.org/pdf/2110.02178.pdf
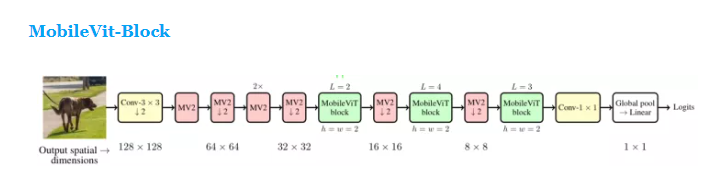
如图为MobileVit整体结构,我们可以看到输入图片(HxWxC)经过一个普通卷积层(Conv3*3)输入到连续的五个MV2中,当(H,W)为32*32时来到了网络的核心部分:MobileVit-Block,接着Block与MV2交叉堆叠,最后一个Block的输出通过一个Conv-1*1 + 全局池化来到了全连接层,紧接着得到最终的输出。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢