
【论文标题】Improving machine learning performance on small chemical reaction data with unsupervised contrastive pretraining
【作者团队】Mingjian Wen, Samuel M. Blau, Xiaowei Xie,b, Shyam Dwaraknath, Kristin A. Persson
【发表时间】2021/11/23
【机 构】加州大学伯克利、劳伦斯伯克利国家实验室
【论文链接】https://doi.org/10.26434/chemrxiv-2021-xr8tf
【代码链接】https:// github.com/mjwen/rxnrep.
机器学习方法通过加速探索化学空间和从数据中得出科学见解,在改变化学发现方面具有巨大潜力。然而,现代化学反应的ML模型,如那些基于图神经网络的模型,必须在大量的标记数据上进行训练,以避免过度拟合数据。在这项工作中,本文提出了一种策略,利用未标记的数据来学习准确的ML模型,以处理小型标记的化学反应数据。本文专注于一个古老而突出的问题--将反应分为不同的家族,并为这个任务建立一个GNN模型。本文首先使用无监督的对比学习在未标记的反应数据上预训练模型,然后在少量标记的反应上对其进行微调。对比性预训练通过使一个反应的两个增强版本的表征彼此相似,但与其他反应不同来进行学习。本文提出了化学上一致的反应增强方法,以保护反应中心,并发现它们是模型从未标记的数据中提取相关信息以帮助反应分类任务的关键。迁移学习的模型在很大程度上超过了从头开始训练的监督模型。此外,它始终比基于传统规则驱动的反应指纹的模型表现得更好,后者长期以来一直是小数据集的默认选择。除了反应分类,基于GNN的反应指纹还可以用来浏览化学反应空间,本文通过查询类似反应来证明这一点。该策略可以很容易地应用于其他预测性反应问题,以发现无标签数据的力量,在有限的标签供应下学习更好的模型。
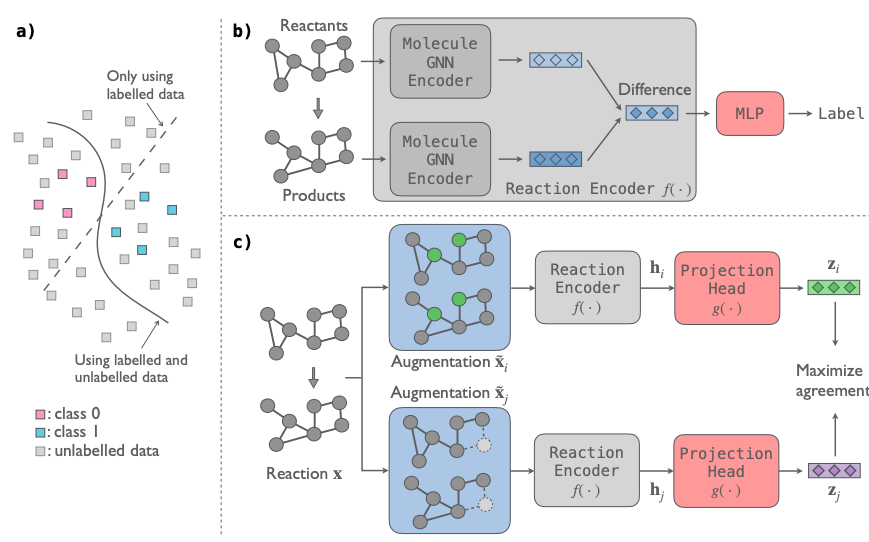
上图为化学反应分类的对比自监督方法的说明性概述。
(a)使用和不使用无标签数据的分类问题的决策边界示意图。利用无标签数据的优势,模型可以发现数据背后的真实模式。
(b) 用于反应分类的预测性GNN模型。该模型将反应的图表征作为输入,并将其映射到反应类型标签。
(c) 对比学习自监督模型,对GNN反应编码器进行预训练。输入反应的数据增强通过反应编码器得到它们的反应指纹hi和hj,然后通过投影头得到向量表示zi和z j,该模型使反应的两个表征之间的一致性最大化。
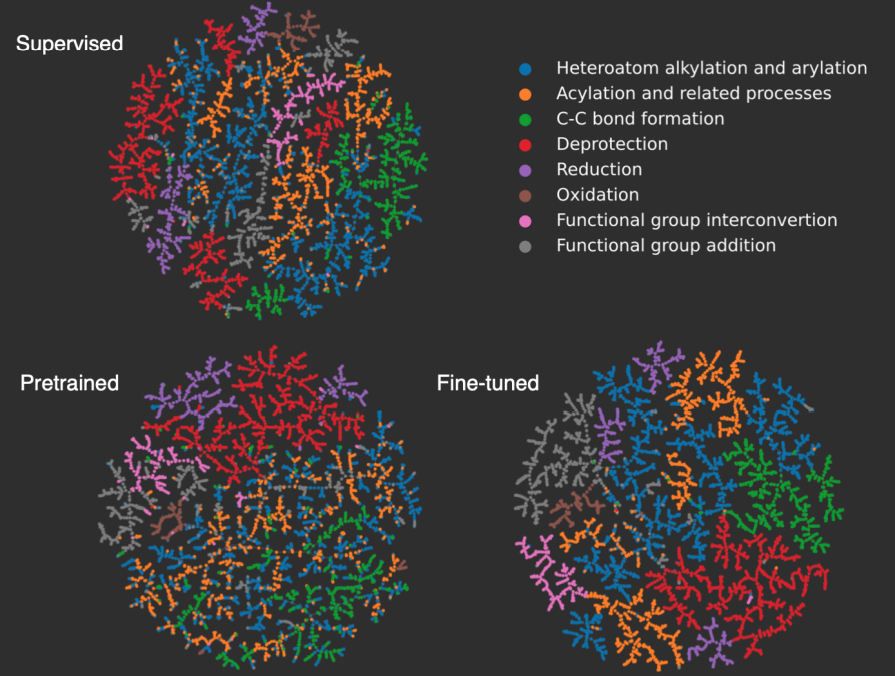
上图展示了反应指纹在二维空间的嵌入。图中的每个点代表一个反应,并根据其超级家族的颜色进行着色。一般来说,相似的反应指纹被嵌入到彼此之间的距离,可以看到Fine-tuned的结果优于其他两种。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢