
论文标题:PolyViT: Co-training Vision Transformers on Images, Videos and Audio
论文链接:https://arxiv.org/abs/2111.12993
作者单位:Google研究院 & 剑桥大学 & 阿兰图灵机构
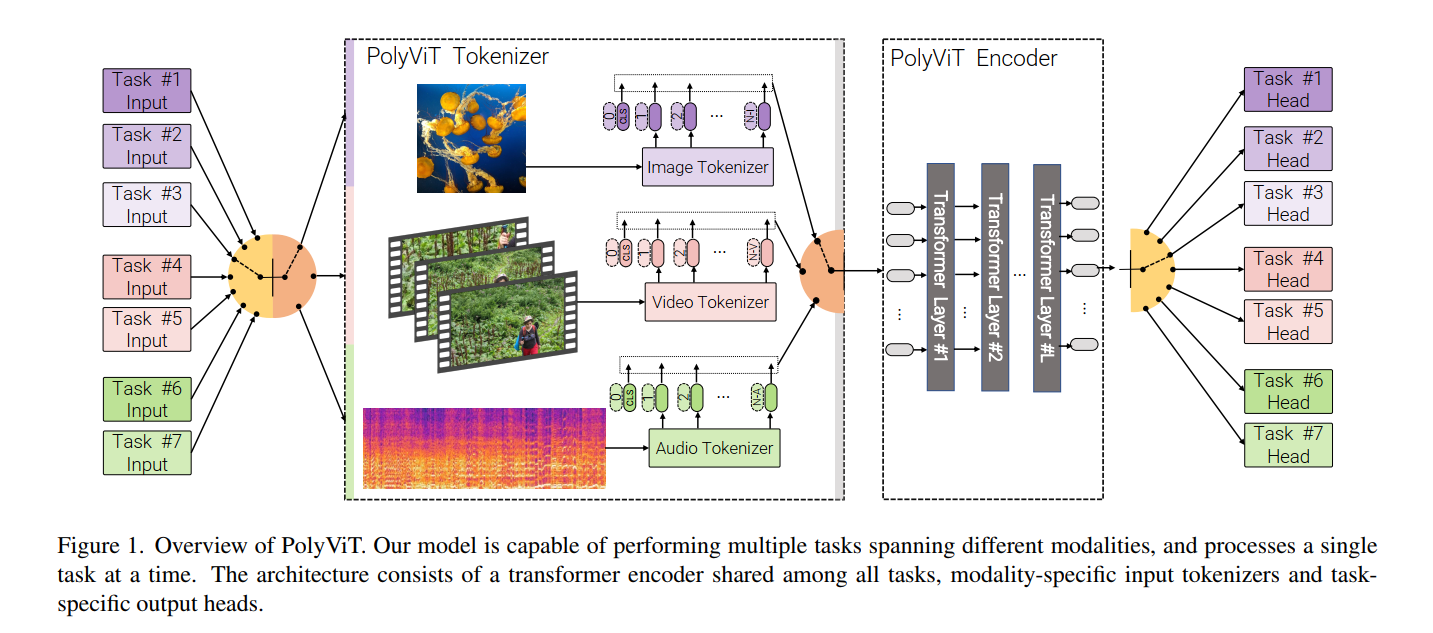
我们能否训练一个能够处理多种模态和数据集的 Transformer 模型,同时共享几乎所有的可学习参数? 我们展示了 PolyViT,这是一个经过图像、音频和视频训练的模型,可以回答这个问题。 通过在单一模态上联合训练不同的任务,我们能够提高每个单独任务的准确性,并在 5 个标准视频和音频分类数据集上取得最先进的结果。 在多种模态和任务上共同训练 PolyViT 会产生一个参数效率更高的模型,并学习跨多个域泛化的表示。 此外,我们表明协同训练实施起来简单实用,因为我们不需要为每个数据集组合调整超参数,而可以简单地调整来自标准的单任务训练。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢