
Mixup [1]是ICLR2017年提出的针对计算机视觉的一项简单的数据增广策略。通过对输入数据进行简单的线性变换(即),可以增加模型的泛化能力,并且能够提高模型对于对抗攻击(Adversarial Attack)的鲁棒性。笔者同时发现,采用Mixup 技术在各种半监督与类半监督任务上(如半监督学习,无监督域迁移等)都能极大提高模型的泛化能力,在某些任务上甚至达到了State-of-the-Art的结果。然而,对于Mixup为什么能够提高泛化能力,以及为什么能够有对对抗攻击的鲁棒性,现有研究仍然没有给出好的解释。在本篇Blog中,我们整理并综述现有对Mixup进行理论解释的文章,同时我们也将对现有的Mixup策略进行综述。
但是,笔者个人对现有的理论研究并不抱有十分赞成态度。几乎所有的理论研究套路都是令,此时Mixup策略中的第二项,即
这一项几乎是微小扰动。现有理论研究都是在这种近似基础上采用泰勒分解,并得出一些结论。但是,在笔者自己所做的实验中,在大部分半监督场景下,当
的取值在
附近时,如
,模型泛化能力会提高一个台阶(如在DomainNet上相对于
的分布会提高4-5个百分点)。对于这种现象,现有所有的理论似乎都失效了,这也是值得研究的地方。
Mixup的介绍与理论分析
Mixup是一种数据增广策略,通过对模型输入与标签构建具有“凸”性质的运算,构造新的训练样本与对应的标签,提高模型的泛化能力。对于具有层次特征的深度学习模型,广义的Mixup[1,2]策略将任意层的特征以及对应的标签进行混合,并构造损失函数如下:
Definition 1. 对于任意两组输入-标签对以及
,令
为
所对应的第
层输入特征(注意到第0层输入特征是原始输入,即
),则Mixup方法可以描述为
其中,函数可以用多种距离计算,如norm-2距离
以及KL散度,而模型
通过损失函数
计算梯度,通过梯度下降法进行更新。
大部分论文将Mixup方法视作一种data-dependent的正则化操作,即要求模型在特征层面对于运算满足线性约束,利用这种约束对模型施加正则化。但是,相比于其他的数据增广策略,Mixup还对标签空间进行了软化,其目标函数往往并不是one-hot的对象,而是一组概率。此外,Mixup并不需要刻意挑选融合的对象,就算是对输入的猫狗进行加权相加,得到看似毫无意义的输入数据以及对应的标签,都能对模型起到良好的引导。近来的工作还发现Mixup对于对抗攻击具有良好的鲁棒性,这些特性使得Mixup成为一个需要独立研究的对象。
在笔者自己的实验中,Mixup,Label-smoothing,Knowledge distillation这些概念往往在实践中都有千丝万缕的联系,它们的共同特点都是对标签空间进行了合理的“软化”。鉴于Mixup已经是我的常用涨点trick之一,对它进行全面的理论分析(然后看看能不能水文章)自然义不容辞。在本节中,我将以近年来Mixup上理论分析做的最深入的文献On Mixup Regularization[4]作为基础,对Mixup背后的理论进行介绍。
正则化(Regularization)是深度学习中模型训练成功的关键。现有的正则化方法分为两种,一种是直接对模型施加显式的正则化约束,或者是利用数据增广的方法,通过数据层面对模型施加隐式正则化约束。显式的正则化约束包括:(1)对于参数施加惩罚,比如正则化项,这往往在程序中采用weight decay的方法进行实现。(2)对于神经网络的表示空间(representation space)或是输出施加扰动或噪声,比如随机dropout,或分块dropout。(3)对于输出进行正则化,比如batch normalization,residual learning,或者是label smoothing(可以增加精度)。隐式正则化约束包括:(1)模型参数的共用(比如从全连接到CNN,出现了filter模块)。(2)优化算法的选择(比如SGD,Adam)。(3)数据增广方法。一般而言,显式的正则化帮助模型在鲁棒性与预测精度上取得优势,而隐式的正则化则增加模型的泛化性。一般而言,隐式正则化与显式正则化方法具有某种等效性,比如对数据施加噪声等价于岭回归
。此外,Dropout方法也与
正则化具有等价性。大量实验表明,Mixup方法可以提高模型对于对抗攻击的鲁棒性,同样可以提高模型的泛化能力和预测精度(ECE损失),但是它的原理却较难理解。一个很自然的想法是,Mixup能达成其他的正则化方法的优点,那么它们必然具有一定的等价性,将Mixup通过形式变换,如果能与其他正则化方法构建等价形式,就能够从理论上解释Mixup的作用。On Mixup Regularization[4]利用泰勒展开,将Mixup与label-smoothing,Lipschitz正则化,输入标准化(如
)以及对输入的随机扰动(random perturbation)建立联系,对于Mixup进行理论分析。
基于模型正则化的理论分析
首先看On Mixup Regularization[4]的第一个定理。
Theorem 1. 对于C分类问题,记神经网络的输出为,标签为
,基于logsoftmax的交叉熵损失为
,对于有N个样本的训练集
,考虑随机变量
,基于Mixup方法的损失函数可以等价推导出如下形式:
其中,满足
它的推断流程如下所述:
对于有N个样本的训练集,令
,基于Mixup方法的经验损失函数 (empirical risk)为
考虑的几个可能的分布函数(只需要观察
的两种可能性):
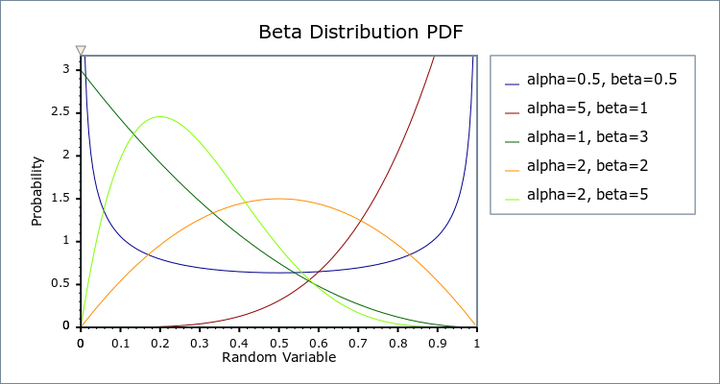
一般而言,Mixup方法普遍选择,这也就意味着
呈现对称分布,且分布值集中于
两头,这就意味着,在公式
中出现的
中,前面系数较小的一项可以看作是额外的扰动项,根据这个思路,我们可以将
拆分为主要项和扰动项,思路如下所述。首先,记
记,那么
式可以写成
注意到,因此
,代入到
中,我们有:
注意到在有限样本下,的顺序可以调换,因此
写作
记,可以展开为
此外,注意到
通过这个变化,我们成功将这一项消除了,并藏在了均值中。因此,对
的一个简单的变换为
这就得到了Theorem 1中的等价形式。 根据这个等价形式,我们可以看到,Mixup策略可以看成是一种向着均值空间的收缩,即将原来的空间
通过
变换到另外一个空间
,在变换的过程中,采用一个范围为
的系数进行压缩,如果
,这个压缩系数会在
附近,压缩的程度比较大;而如果
,这个压缩系数则会在
附近,等价于中心化。对于标签空间
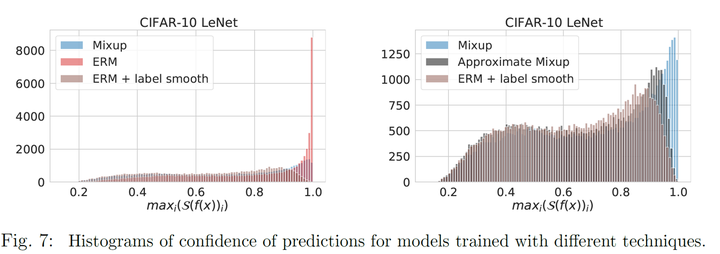
而言,这种方法等价于label-smooth,在实验中,这种变换会使得预测的结果不至于太大。实验结果表明,在进行Mixup或label-smooth后,模型预测的最大概率
的分布变小了,极限情况(如
)也变小了。
此外,注意到在训练过程中,对于训练数据进行了变换,那么同样在测试过程中也应当进行相似的变换,即在输入的时候,应当将先变换进
空间,即
。得到模型对
的预测
之后,再将其变换到真实标注空间
,即
。On Mixup Regularization[4]发现,这种变换能够显著提高使用Mixup进行训练的模型的精度和准确性,并且精度的评估指标ECE也上升了。
至此,我们从靠近均值的中心化变换(space transform)以及标签平滑化(label-smooth)两个角度对Mixup进行了研究。注意到我们在式中还引入了残差项
,显然,它们的期望为0,并且当
的时候,它们的取值范围也不会离0很远。因此,我们在
这种条件下,将这些残差项视作微小扰动,通过泰勒展开研究Mixup在噪声正则化上的效果。
先回顾在附近的二阶(Quadric)泰勒展开公式:
注意到,因此在
的二阶泰勒展开中,它们的一阶导数都可以忽略,此时我们利用泰勒公式将损失函数
写成
注意到,这里利用的结论为
其中,表示把矩阵按行拉平,然后做内积,我们利用这个结论把
写成为
,同理可得后面两项,然后再将期望代入。此外,我们还要利用以下三条公式:
此外,我们记
注意
容易得到
此外,注意到
因此,我们可以利用这个关系,将映射到
,此时有
,其他情况也可以依次类推,可以得到如下关系:
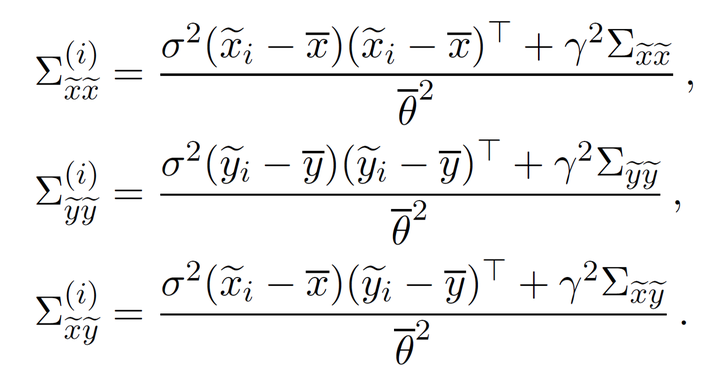
其中,。
利用上述关系,On Mixup Regularization[4]给出了如下定理二用以解释Mixup方法的影响
注意,表示基于Jacobian正则化的约束。联系Dropout等价于惩罚
在训练点的二范数,Mixup方法通过对模型梯度与Jacobian矩阵的距离进行惩罚来增加模型的泛化性,而这种惩罚并不是直接赋予的,而是通过令模型模仿在输入和标注空间中的线性关系,从而间接施加约束。此外,我们也注意到,Mixup的正则化效果也与输出和输出之间的相关性有关,这也解释了单独对输入或者标签进行Mixup的效果比起标准的Mixup弱很多。
对于交叉熵损失,我们记
,并令
此时在交叉熵损失下的二阶泰勒展开为
其中
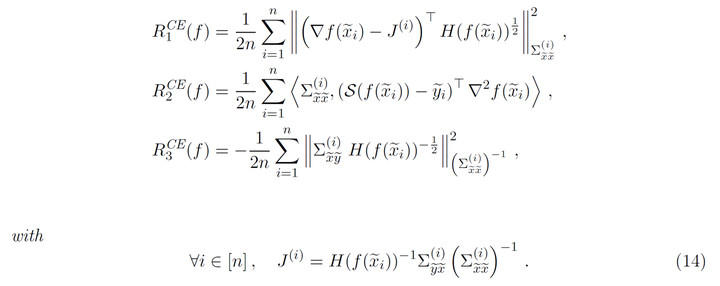
注意到,如果预测概率过大,如最大的概率接近于1,最小的概率接近于0,那么
中所有的项都会趋向于0,那么正则化效果就会消失,因此对于标签空间也进行Mixup可以防止预测过于自信,从而确保正则化有用,这就解释了为什么只对输入进行Mixup效果差,这是因为没有类似于label-smoothing的作用,Mixup的正则化效果消失了。
基于流形学习的理论分析
Manifold Mixup[2] 提出了上述公式中所述的流形学习策略,相对应的,它将目标损失函数写成
Manifold Mixup中的核心结论是,只要进行mixup的特征空间的维数大于
,那么我们就可以找到一个线性函数
,以及一个深度表征映射
,令目标损失函数为0。它的证明方法很简单,因为
,所以一定存在一个从
到分类空间的映射,简单而言,存在
,使得
。那么,我们只需要对于每一个属于第
类的样本
,满足
为矩阵
的第
列就可以了,这样
,此时目标损失函数
。
Manifold Mixup[2] 又指出,在这种条件下,所有数据点在表征空间(representation space)上都会落在一个维数为的子流形上。这当然也很好理解,此时
上的大部分表达都与
分类结果建立了联系,剩下的自由维数自然只有
维。然后Manifold Mixup[2] 得到了如下结论:首先,当Mixup损失函数
最小为0时,所有数据的表征都在一个维数为
的子流形上,因此Mixup损失函数鼓励模型学习有效的分类表征。如果
,那么所有的数据都会映射到同一个点,这个点代表数据的分类。
但是,笔者觉得Manifold Mixup的这一套说辞陷入了一个奇怪的逻辑循环。作者认为,当Mixup损失函数最小为0时,所有数据的表征都在一个维数为
的子流形上,因此证明了Mixup的正则化效果。但是上面的证明方式说明的是,如果我们能将所有的输入数据都按照它们对应的标签整齐地映射到
中,此时Mixup损失函数为0,这并不能说明Mixup的正则化效果。实际上,对于任何一个分类问题,本质上都是学习一种整齐的映射。我们都希望神经网络能够学到将同一类数据映射到同一个表征上的能力,而表征和分类的对应关系学习则非常简单。因此,整个分类问题的关键应该是如何学到一个映射,能够将每一个属于第
类的样本
,满足
为某一固定矩阵
的第
列,而由于输入是非常复杂的,这个映射是很难学到的,也是机器学习的基本问题。作者假设这个基本问题已经解决了,然后再进行一系列解释,这明显是一个循环论证。
此外,笔者实现了Manifold Mixup[2]中的算法,见我的Github,实践证明,相比于直接对输入进行Mixup,在特征空间进行Mixup需要消耗3倍的训练时间,此外,对于深层特征Mixup并不会增加最后的结果,一般对于输入和第一,第二个maxpool后的特征进行Mixup会取得较好的效果,而对于更深层的特征则不会有用。按照作者的推论,当,Mixup的效果最好,这显然是不太对的。因此,我并不赞成本文的论证。但是Manifold Mixup[2]的实验做的还算完善,且在生成模型方面也做出了一些贡献。
现有Work的Mixup方法
接下来,我们对现在比较常用的Mixup方法按它们的四个应用动机,即模型正则化、半监督学习、域迁移以及生成模型进行分类,并对已有工作进行综述,看看它们是怎么work(灌水)的。
模型正则化Mixup
AdaMixup指出了一个现象,即进行Mixup的时候,可能混合样本与数据点会相撞,如下图所示:
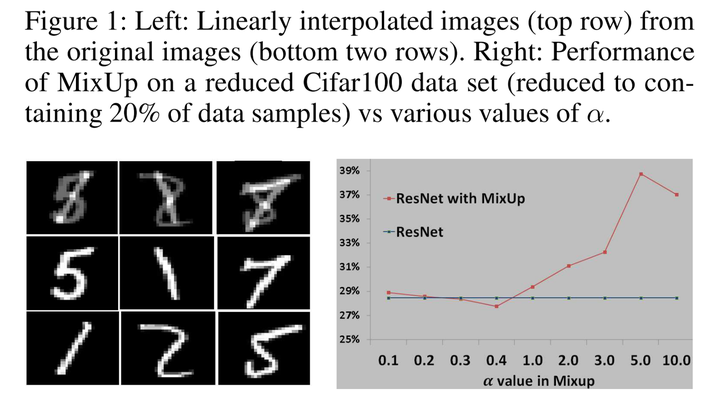
经过Mixup后的图像会与数字8相撞,但是它们的标签则不是数字8,这会让模型的效果变糟。作者同样做了Cifar100上的实验,发现随着停留在
附近,效果就会变差,作者得出这种现象会令Mixup带来负影响,因此我们训练的时候应该避免这种现象。(但是我觉得这个论据有点扯淡,自然图像的Mixup怎么会和已有的样本撞了呢?你用MNIST的数据应该用MNIST的实验啊,用Cifar100的实验算怎么回事。)怎么避免呢?作者提出新增一个分类器网络,判断输入是Mixup的样本还是原始样本:
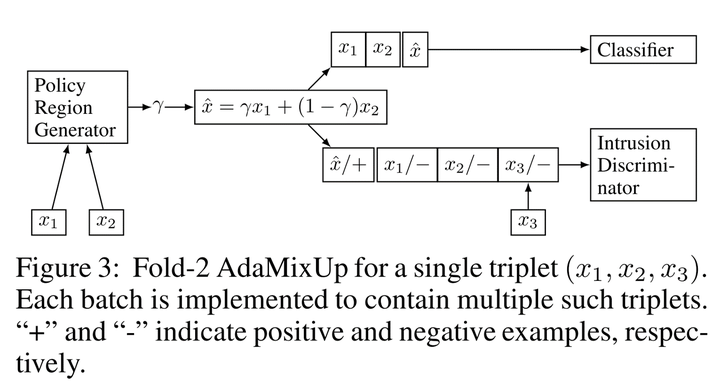
然后训练一个自适应的,这个
能够尽量保证进行Mixup不会和原数据点相撞。作者证明这种自适应策略能提点。
CutMix[6]指出,传统的Mixup操作可以看成是一种信息混合。比如我们通过混合0.9猫+0.1狗的时候,本质上是把两张图中0.9和0.1的信息进行混合了。但是,对于图像而言,信息往往是连续的,因此相比于直接相加,用一张图像的部分连续信息去代替另一张图像的连续信息是在视觉角度更加make sense。CutMix[6]就是基于这种动机提出的,它的想法是,先选取一个,然后选择图像中面积比例刚好为
的一片区域,选择两个图像,将它们的对应区域进行互换,而标签则为两张图像标签的加权和,如下图所述。

但是,CutMix[6]有一些缺陷,比如,如果裁剪的是图像的背景部分,那么CutMix并没有改变标签,但是我们仍然会按Mixup的方法计算标签,这会提供错误的标签。此外,CutMix仅仅对输入进行了Mixup,没有用上更好的Manifold Mixup[2]。后面的工作基于这两个改进方向提出了一些新的Mixup策略。
PatchUp将CutMix[6]泛化到了特征空间,分为两步:首先,选择一个输出特征层,并从特征层中剪切出一些feature block,然后,对这些feature block进行Mixup。相比于CutMix[6]的直接替换,作者提出了一种SoftMixup方法,就是将要替换的feature block先单独拿出来进行Mixup,再填补原来的空间,如下图所示。
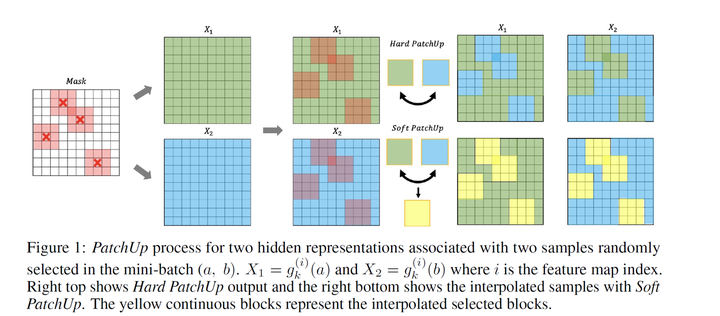
PuzzleMix[7]针对CutMix可能会Mixup背景这一问题,提出先对输入图像采用传统方法计算显著性信息,然后将信息密度最高的地方进行CutMix,从而改善最后的结果。
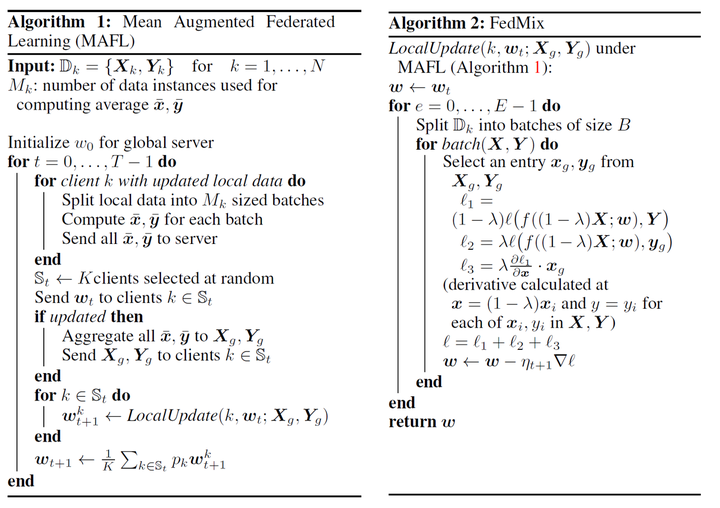
此外,在联邦学习成为热门话题的现在,如何分布式地进行Mixup也是一个重要的研究方向。基于之前对Mixup方法进行的一些泰勒展开和泛化研究,FedMix[8]提出了联邦Mixup方法。它同样假设,此时我们忽视扰动
,将损失函数写为
作者称之为Mean Augmented Federated Learning (MAFL)。因此,作者提出,我们只需要获得每一个client的的信息,就可以进行Mixup。但是,这种方法需要在每一个Batch都对均值进行通信,这会泄露隐私,并且还会令通信的花销增大。所以作者又莫名其妙提出了一种替代损失,通过假设
,损失函数
可以泰勒展开,对进行求导得到一阶泰勒展开为
作者称这种减少了计算开销的近似损失为FedMix。在联邦学习的环境下,MAFL和FedMix通过获得不同client在每一个Batch上的的信息进行分布式Mixup,伪代码如下:
半监督学习Mixup
Mixup可以为半监督学习产出质量较高的伪标签,通过混合有标注和无标注的图像,并混合有标注的真实标签与模型对无标注图像的预测标签,Mixup可以学到无标注图像的监督信息。ICT[9] 首次提出了利用一致性损失进行半监督学习,损失函数为
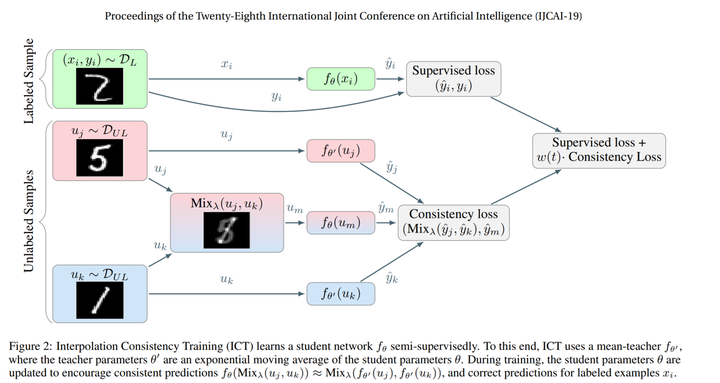
SHOT-VAE[10]通过最佳运输理论,将输入空间的Mixup与VAE模型的因子分布建立联系,从而得到了更好的半监督自动编码器模型,并打破了Good ELBO, Bad Inference的瓶颈。
域迁移学习Mixup
Domain Adaptation可以看作是源域有标签,目标域无标签的跨域半监督学习。基于这个思路,Mixup可以为目标域提供高质量的伪标签。 现有将Mixup用于域迁移学习的文献较少,一般与传统的域迁移方法配套使用,使用方式包括:(1)对抗训练+域内样本Mixup,如Dual Mixup[11],Virtual Mixup[13],将Mixup简单看作是正则化方法,用于增强模型学到的特征多样性;(2)联合使用用域内Mixup以及域间Mixup[12],在进行域间Mixup的时候,对于无标注的目标域,采用多种方法获得样本的伪标签,通过伪标签与真标签的Mixup获得模型的预测目标,伪标签的获得是这一类方法成功的关键,文献[12]采用多种数据增广方法构造不同的模型推断,然后对这些推断做平均以获得伪标签,文献[14]采用知识蒸馏的方法,令得到smooth过的标签;(3)使用类似于Teacher-Student的协同训练(Co-Training)训练多个分类器,然后用互相提供的标签与具有真实标签的样本混合,提供Mixup的伪标签。这种方法现在应用于半监督(Semi-supervised)域迁移中[15],通过半监督学习与无监督学习训练两个分类器,然后利用彼此的标签提供Mixup的混合素材,最后利用一致性损失进行训练。这里Mixup所扮演的功能主要是降低伪标签的噪声。
生成模型的Mixup
Manifold Mixup[2]指出,可以用Mixup对GAN进行正则化。简单而言,对于Fake Image 与**Real Image **
,采用
,标签为
,我们可以用如下损失函数训练模型:
注意,这个混合必须是跨域的,即对Fake-to-Fake与Fake-to-Real进行混合,而在Real Image这个域内,比如Real-to-Real的混合,进行Mixup反而会降低模型的生成效果,因为实际上Real-to-Real出的混合图像并不是Real Image,这也是值得研究的问题,但是总之这种混合对于生成模型的改善是有意义的。
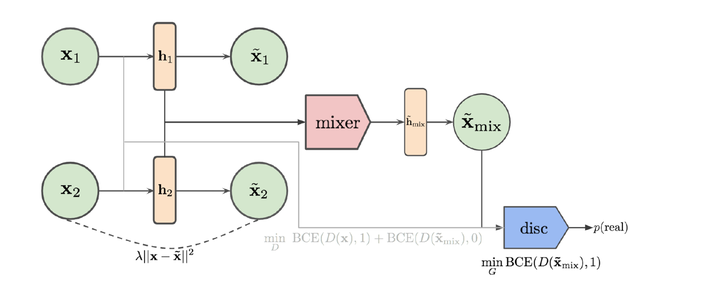
此外,Mixup还可以用于VAE和GAN混合的生成模型训练[5],如下图所示,整个生成模型由一个autoencoder和一个discriminator组成。其中,autoencoder将输入映射到特征
,并将特征
通过解码器映射回原空间
,用经典的重构损失进行训练,要求
之间的距离尽量接近。discriminator则尽量区分
,用二分类损失训练。此外,还要求autoencoder的生成结果能够迷惑discriminator。因为autoencoder是一个一对一生成,为了尽量让discriminator能够利用尽可能多的样本,文献[5]提出,对于两个特征
,可以通过在特征空间融合,得到
,这种
可以通过两种方式得到,一种是基于Manifold Mixup[2],即
另一种是基于CutMix[6],即先选一个,然后用
构造一个伯努利分布
,然后采样一个与
相同维度的mask
,得到
根据可以得到
,利用
可以训练discriminator与autoencoder。训练discriminator时,要求它能够将
识别为Fake,而训练autoencoder时,要求尽量能够骗过discriminator,将
识别为Real。
参考文献
[1] Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond empirical risk minimization[J]. arXiv preprint arXiv:1710.09412, 2017.
[2] Verma V, Lamb A, Beckham C, et al. Manifold mixup: Better representations by interpolating hidden states[C]//International Conference on Machine Learning. PMLR, 2019: 6438-6447.
[3] Guo H, Mao Y, Zhang R. Mixup as locally linear out-of-manifold regularization[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 3714-3722.
[4] Carratino L, Cissé M, Jenatton R, et al. On mixup regularization[J]. arXiv preprint arXiv:2006.06049, 2020.
[5] Beckham C, Honari S, Verma V, et al. On adversarial mixup resynthesis[J]. arXiv preprint arXiv:1903.02709, 2019.
[6] Yun S, Han D, Oh S J, et al. Cutmix: Regularization strategy to train strong classifiers with localizable features[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 6023-6032.
[7] Kim J H, Choo W, Song H O. Puzzle mix: Exploiting saliency and local statistics for optimal mixup[C]//International Conference on Machine Learning. PMLR, 2020: 5275-5285.
[8] Yoon T, Shin S, Hwang S J, et al. FEDMIX: APPROXIMATION OF MIXUP UNDER MEAN AUGMENTED FEDERATED LEARNING[J].
[9] Verma V, Kawaguchi K, Lamb A, et al. Interpolation consistency training for semi-supervised learning[J]. arXiv preprint arXiv:1903.03825, 2019.
[10] Feng H Z, Kong K, Chen M, et al. SHOT-VAE: Semi-supervised Deep Generative Models With Label-aware ELBO Approximations[J]. arXiv preprint arXiv:2011.10684, 2020.
[11] Wu Y, Inkpen D, El-Roby A. Dual mixup regularized learning for adversarial domain adaptation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 540-555.
[12] Yan S, Song H, Li N, et al. Improve unsupervised domain adaptation with mixup training[J]. arXiv preprint arXiv:2001.00677, 2020.
[13] Mao X, Ma Y, Yang Z, et al. Virtual mixup training for unsupervised domain adaptation[J]. arXiv preprint arXiv:1905.04215, 2019.
[14] Sahoo A, Panda R, Feris R, et al. Select, Label, and Mix: Learning Discriminative Invariant Feature Representations for Partial Domain Adaptation[J]. arXiv preprint arXiv:2012.03358, 2020.
[15] Deep Co-Training with Task Decomposition for Semi-Supervised Domain Adaptation.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢