
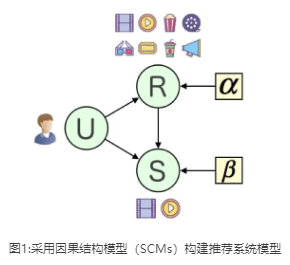
推荐系统的训练数据中存在稀疏和不平衡的现象,对提高推荐的性能挑战很大。为了应对挑战,诺亚方舟实验室联合中国人民大学、UCL的学者,提出了采用因果推理框架构造推荐系统模拟器,通过该模拟器生成大量反事实数据用于处理数据稀缺问题,并将研究成果撰写论文,Top-N Recommendation with Counterfactual User Preference Simulation,发表于CIKM2021。本文设计的核心在于回答一个反事实的问题:“如果推荐的商品不同,用户的决定会是什么?”。为了回答这个问题,本文采用一系列结构方程模型(SEM)构建模拟器来描述推荐过程。通过该模拟器生成大量未被记录在数据样本当中的推荐列表并根据学习到的SEM模拟用户反馈以生成新的训练样本。与此同时,本文设计了一种基于强化学习的方法来发现更多信息量的训练样本。考虑到学习到的SEMs不可能是完美的,本文从理论上分析生成样本数与模型预测误差之间的关系。
论文链接:https://arxiv.org/abs/2109.02444
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢