
传统视频压缩方法多采用残差编码框架,虽简单有效但却并不是最优解,其熵往往大于或等于条件编码的熵。通过从残差编码到条件编码的转换,微软亚洲研究院多媒体计算组的研究员们构建了一种基于上下文的视频压缩框架(DCVC),为基于深度学习的视频压缩提供了新思路和新方法。实验表明,该视频压缩框架比常用的残差编码框架有更低的信息熵下界,且能够自适应学习帧内编码和帧间编码,适用于对高频细节的恢复。作为一种可拓展性非常强的框架,DCVC 也将在未来继续发挥其强大的压缩性能。相关论文已被 NeurIPS 2021 接收。

论文链接:https://arxiv.org/abs/2109.15047
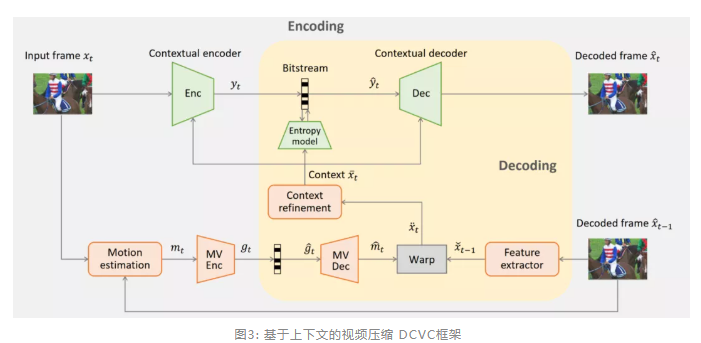
DCVC 实现框架如图3所示。至于如何学习上下文特征,研究员们首先设计了一个特征提取器将之前解码帧从像素域转换到特征域,同时利用运动估计去学习运动向量。该运动向量在经过编码和解码之后会指导网络从哪里提取特征。考虑到运动补偿引发的空间不连续性,研究员们又设计了一个上下文改进模块去生成最终的上下文特征。该上下文特征通过并以并联的方式作为编码器和解码器的条件输入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢