
概念是人类认知从具体进入抽象的第一步,也是人类认知世界的基石。概念知识图谱是一种特殊的知识图谱,在语义搜索、自动问答等场景具有广泛的应用价值。例如,微软开发了 Microsoft Concept Graph 可以帮助机器更好地理解人类语言进而提升语义搜索效果。许多电商平台(如阿里巴巴和亚马逊)将产品分为不同粒度的层次结构,以便客户可以轻松地搜索和导航不同分类,找到他们想要购买的商品。然而,以往的概念图谱构造方法通常只从文本中抽取高频率、粗粒度和静态的概念实例。在实际应用中,其较难覆盖长尾和细粒度概念信息,且存在更新困难的问题。针对这一问题,浙江大学和阿里巴巴的算法工程师们一起提出了一种全新的自动化概念图谱构建方法,其能够自动的从海量文本及半结构化数据中构建细粒度的中文概念层次结构,并将其落地到了业务应用中。
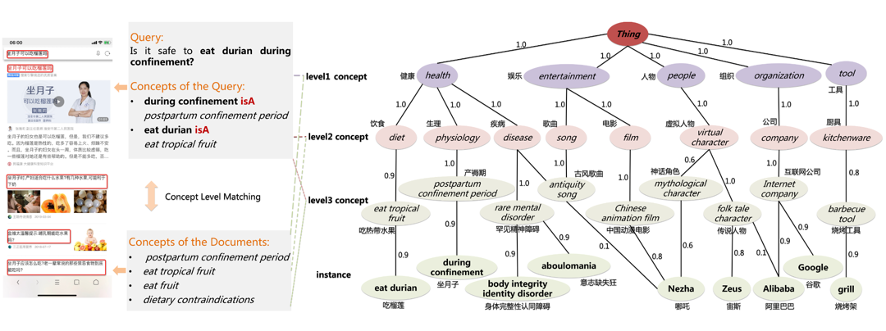
首先看一些真实的搜索引擎的例子。当用户输入"情人节礼物送男友"或者"感冒吃什么"的query的时候,传统的基于语义或向量召回的搜索引擎,在一定程度上仅仅根据字面意思做语义匹配和召回,很难理解用户的深层诉求。如果能够构建一个大规模的概念分类体系,把搜索的结果或商品打上相应的概念标签,显然可以提升搜索用户体验。
 这里对搜索业务中的语义理解起很大作用的图谱其实是概念图谱。我们从业务本身的视角出发,仔细思考了什么样的知识图谱对思索更加有帮助。我们发现,首先搜索其实非常需要细粒度的概念理解。其次,搜索中的概念并不是一成不变的。他是存在一定概率的且动态变化的。比如对于哪吒这一query, 在不同的时期,用户的搜索意图以及概念的分布也会完全不一样。
这里对搜索业务中的语义理解起很大作用的图谱其实是概念图谱。我们从业务本身的视角出发,仔细思考了什么样的知识图谱对思索更加有帮助。我们发现,首先搜索其实非常需要细粒度的概念理解。其次,搜索中的概念并不是一成不变的。他是存在一定概率的且动态变化的。比如对于哪吒这一query, 在不同的时期,用户的搜索意图以及概念的分布也会完全不一样。

基于以上的发现,我们设计了一个大规模的概念知识图谱AliCG。AliCG 主要分为四个层次,分别是实例层,包含个实体和一些短语; level 3层,包含了细粒度的概念; level 2 层,包含了一些实体类型的知识,以及level 1层它包含了一些领域的信息。那么怎么构建这个大规模的概念知识图谱呢?
这幅图简单展示了AliCG的构建过程。主要分为三个部分,首先是基于模板匹配的头部概念挖掘,其次是基于短语挖掘和序列标注的长尾概念抽取,最后是基于用户行为的概念分布估计。
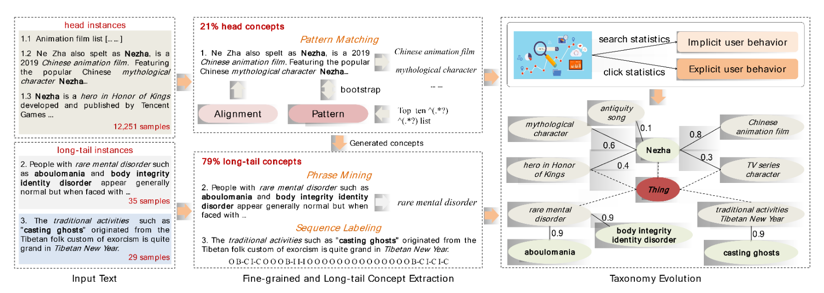
针对细粒度概念抽取,我们采取了基于boostraping和模板匹配的方式来进行概念的挖掘。这里这对搜索业务场景,我们基于query和tile中的概念一致性对抽取的概念进行过滤。

针对长尾概念挖掘,我们采用了基于AutoPhrase的短语挖掘算法,并基于中文的特点将分词信息,长度等作为概念的约束,并基于树模型训练了一个概念分类器来对短语打上概念标签。

最后,我们基于显示和隐式的用户行为估计并更新概念分布。

实验结果表明,AliCG的概念构建方法优于传统的基线模型,并且能够根据大量网络数据自动的更新概念的分布信息。

这里我们基于AliCG的构建方法从公开数据中抽取并构建了一个开放的中文细粒度概念知识图谱。可以看到我们对于”浙大“这个实体,可以获取大量的细粒度概念信息,对于搜索非常有帮助。

我们的数据也已经开源了,欢迎大家下载使用,如果大家对我们构建的方法细节感兴趣,欢迎查看我们在KDD 2021上发表的关于AliCG构建的论文AliCG: Fine-grained and Evolvable Conceptual Graph Construction for Semantic Search at Alibaba 。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢