
WuDao Data Cleaner作者:薛钊、袁莎、赵撼宇、马全跃
WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量的预训练数据集。
智源研究院于2021年6月份发布了全球最大的预训练数据集WuDaoCorpora 2.0,包含文本、多模态和中文对话三部分,分别致力于构建微缩中文世界、打破图文模态壁垒、浓缩对话核心规律,从而形成多维度世界顶级数据库,促进中国的通用人工智能发展。
WuDaoCorpora Cleaner是WuDaoCorpora配套的数据清洗工具,它采用20多种清洗规则,能从原始网页清洗出最终数据集,注重隐私数据信息的去除,源头上避免隐私泄露风险。
WuDao Data Cleaner的八大核心能力:
-
文字富集类页面文本数据智能提取;
-
基于自建乱码库对乱码文本数据的判断;
-
基于自建繁体字库对含有繁体字的网页文本进行转简;
-
自动识别文本中不完成的句子以及大段的换行、空格;
-
自动识别文本中不完整的xml、html片段;
-
自动识别文本中的链接、异常符号;
-
自动识别隐私数据并基于策略剔除;
-
基于阈值对文本进行自动筛选;
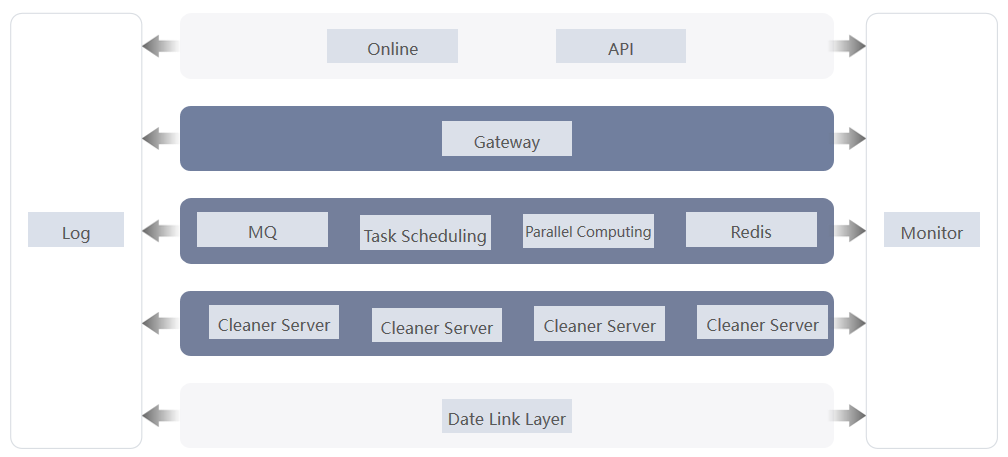
系统技术架构,如下图所示:
系统展示(体验平台):
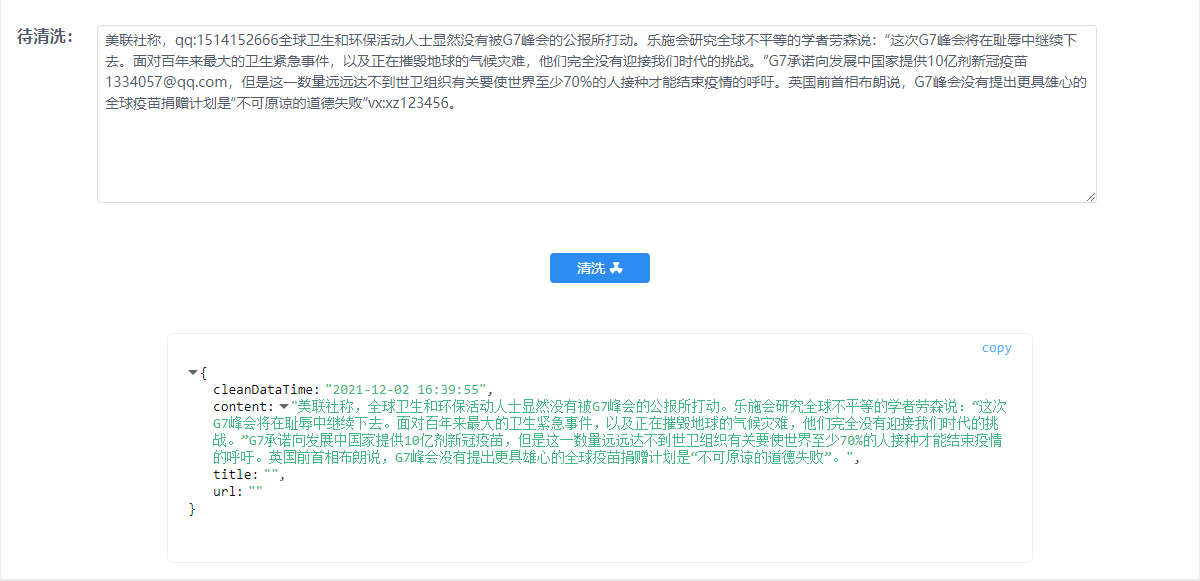
1. 敏感信息的剔除,如下图所示:
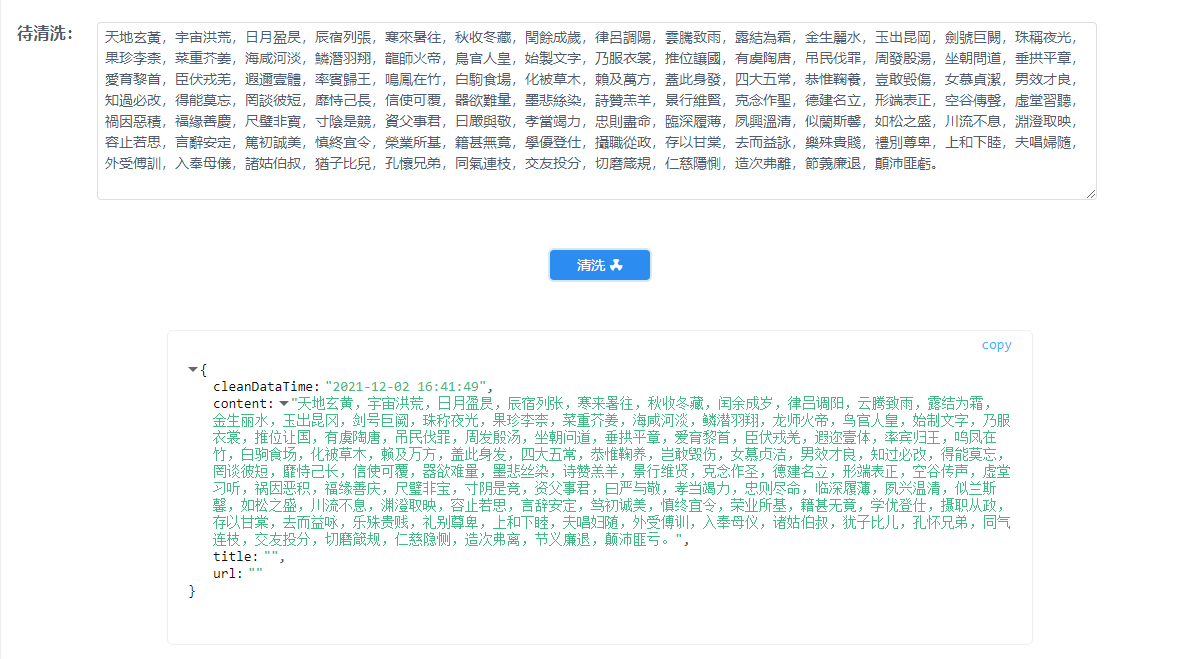
2. 中文繁体字自动转简体字,如下图所示:
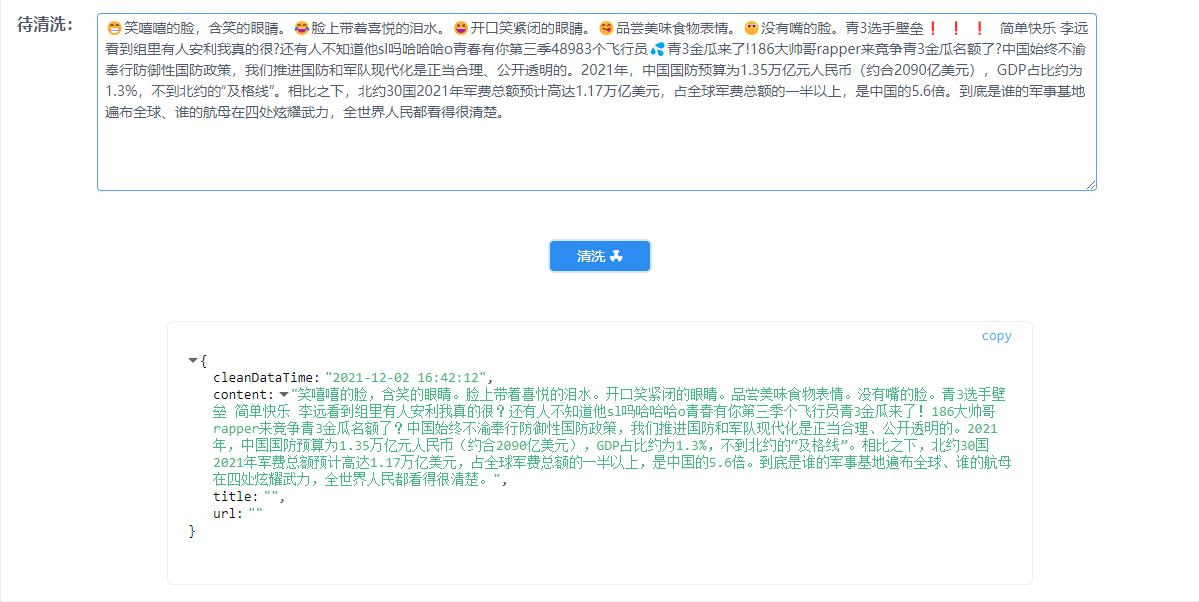
3. 特殊符号的剔除,如下图所示:
4. 文本内容杂乱的处理,如下图所示:
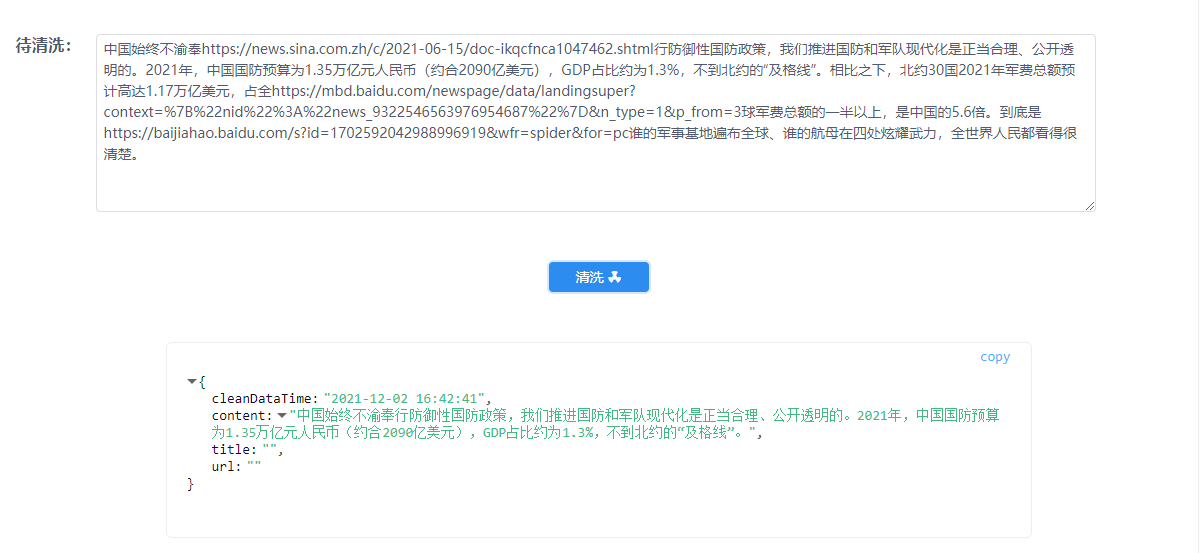
以上,只展示四种文本处理能力,更多能力请访问体验平台进行体验。
目前API已对外开放!
体验链接:https://wudaoai.cn/cleaner
"悟道"官网:https://wudaoai.cn
扫码加入WuDao Data Cleaner技术交流群

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢