
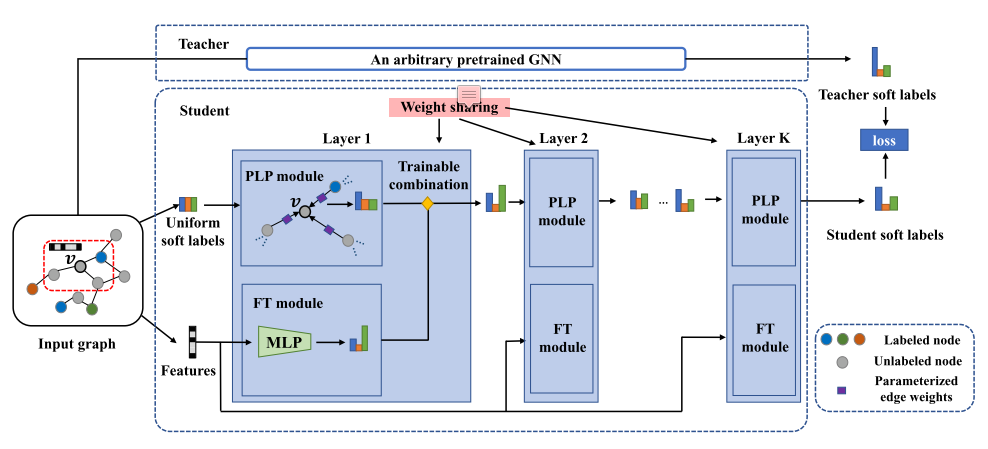
1.【WWW2021】Extract the Knowledge of Graph Neural Networks and Go Beyond it: An Effective Knowledge Distillation Framework
作者:北京邮电大学杨成老师
导读:本文提出了一个基于知识提炼的框架。该框架提取任意学习的GNN模型(教师模型)的知识,并将其注入精心设计的学习模型中。学生模型采用两种简单的预测机制建立,即标签传播和特征转换,这两种机制自然地分别保留了基于结构和基于特征的先验知识。具体来说,将学生模型设计为参数化标签传播和特征转换模块的可训练组合。因此,有学问的学生可以从先前的知识和GNN教师的知识中获益,从而进行更有效的预测。作者在五个公共基准数据集上进行实验,并使用七个GNN模型作为教师模型,包括GCN、GAT、APPNP、SAGE、SGC、GCNII和GLP。实验结果表明,学习型学生模型的表现优于相应的教师模型1.4%∼ 平均为4.7%。
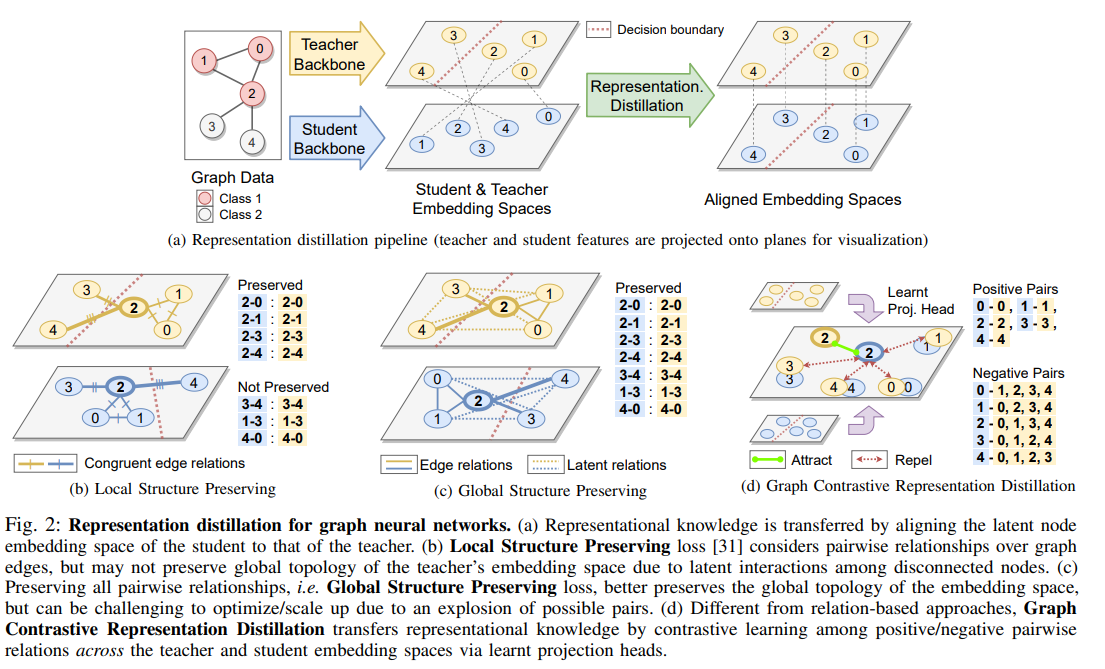
2.【arXiv:2111.04964】On Representation Knowledge Distillation for Graph Neural Networks
导读:过去关于GNNs分解的工作提出了局部结构保留损失(LSP),它匹配学生和教师节点嵌入空间中的局部结构关系。在这篇论文中,作者做出了两个关键贡献:从方法论的角度,作者研究了对于GNNs来说,保留教师如何嵌入图形数据的全局拓扑是否是一个更有效的蒸馏目标,因为现实世界中的图形通常包含潜在的交互和噪声边缘。预定义边上的纯局部LSP目标无法实现这一点,因为它忽略了断开连接的节点之间的关系。作者提出了两种更好地保持全局拓扑结构的新方法:(1)全局结构保持损失(GSP),它将LSP扩展到包含所有成对相互作用;(2)图形对比表征蒸馏(G-CRD),它使用对比学习将学生节点嵌入到共享表征空间中的教师节点嵌入对齐。
本期内容:许轶珂 王嘉豪 蒙盼盼
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢