
论文标题: A Unified Pruning Framework for Vision Transformers
论文链接:https://arxiv.org/abs/2111.15127
作者单位:南京大学
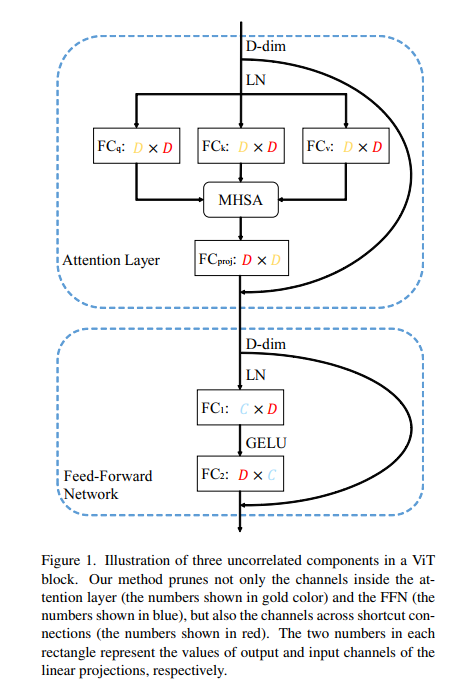
最近,视觉Transformer (ViT) 及其变体在各种计算机视觉任务中取得了令人鼓舞的性能。然而,ViT 的高计算成本和训练数据要求限制了它们在资源受限环境中的应用。模型压缩是加速深度学习模型的有效方法,但对压缩 ViTs 的研究较少。之前的很多工作都集中在减少代币的数量上。然而,这条攻击线打破了 ViTs 的空间结构,很难推广到下游任务中。在本文中,我们为 ViTs 及其变体的结构修剪设计了一个统一的框架,即 UP-ViTs。我们的方法侧重于修剪所有 ViT 组件,同时保持模型结构的一致性。大量的实验结果表明,我们的方法可以在压缩的 ViTs 和变体上实现高精度,例如,UP-DeiT-T 在 ImageNet 上实现了 75.79% 的准确度,在相同的计算成本下比 vanilla DeiT-T 高 3.59%。 UP-PVTv2-B0 将 PVTv2-B0 的 ImageNet 分类准确率提高了 4.83%。同时,UP-ViTs 保持了令牌表示的一致性,并在对象检测任务上获得了一致的改进。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢