
由于近年来大规模平行语料库的普及和计算机硬件计算能力的提升,基于神经网络的机器翻译方法得到了快速的发展且展现了优异的翻译效果,它也逐渐取代了基于统计的机器翻译方法成为了当前机器翻译的主流方法。尽管如此,神经机器翻译本质上是一种依靠数据驱动的算法,神经网络主要通过观测的数据更新自己的参数从而得出一般性的规律,因此主流的神经机器翻译模型都需要经过大量的平行语料训练才能够达到可商用的翻译效果,而小语种的平行语料资源匮乏,受到语料规模的限制,机器对小语种的翻译效果仍然不尽人意。
本系统的核心是神经机器翻译模型,它主要聚焦于波斯语、印地语、印尼语、阿拉伯语4个小语种到中文的翻译。为了缓解小语种的平行语料资源不足的问题,我们收集了公开的平行语料库中对应的小语种与中文的平行语料,然而这些平行语料的来源各异,对齐质量也参差不齐,为了保证神经机器翻译模型的翻译效果,我们还依托于标准化的平行语料库构建流程构建了小语种和中文之间高质量的平行语料,为了尽可能扩大语料覆盖的领域,我们爬取了多个领域的新闻网站获取小语种的单语语料,然后采用人工翻译的策略将其翻译为中文,我们对构建的语料进行了三次质检以保证它的质量。除此以外,我们还采用了多种数据增强方法对已有的平行语料进行扩充以提升模型的鲁棒性和翻译效果。
为了简化系统的部署流程,我们将系统封装在Docker容器中,消除了部署和开发两个过程中系统运行环境的差异,只需要先导入Docker镜像后将镜像启动为Docker容器就可以在任意服务器部署本系统。同时为了降低系统配置难度,我们将与翻译服务相关的参数统一用一个配置文件管理,可以根据需要灵活修改系统中相应的参数。
为了提升系统的翻译速度,本系统采用批量翻译的策略最大化GPU的使用效率,同时采用增量解码的方式避免冗余计算,以加快译文生成的速度。由于翻译请求通常是离散的,为了最大化并行计算的效率,本系统采用队列存储翻译请求,并将队列中的请求划分为各个批次进行批量翻译。尽管系统采用了多种策略提升其翻译速度和计算效率,当面对极端情况下的高并发翻译场景时,系统的吞吐量可能会受限于其能够使用的硬件资源,为了缓解这个瓶颈并尽可能利用已有的硬件资源,本系统还实现了多GPU部署和翻译的功能。
(1)系统界面展示
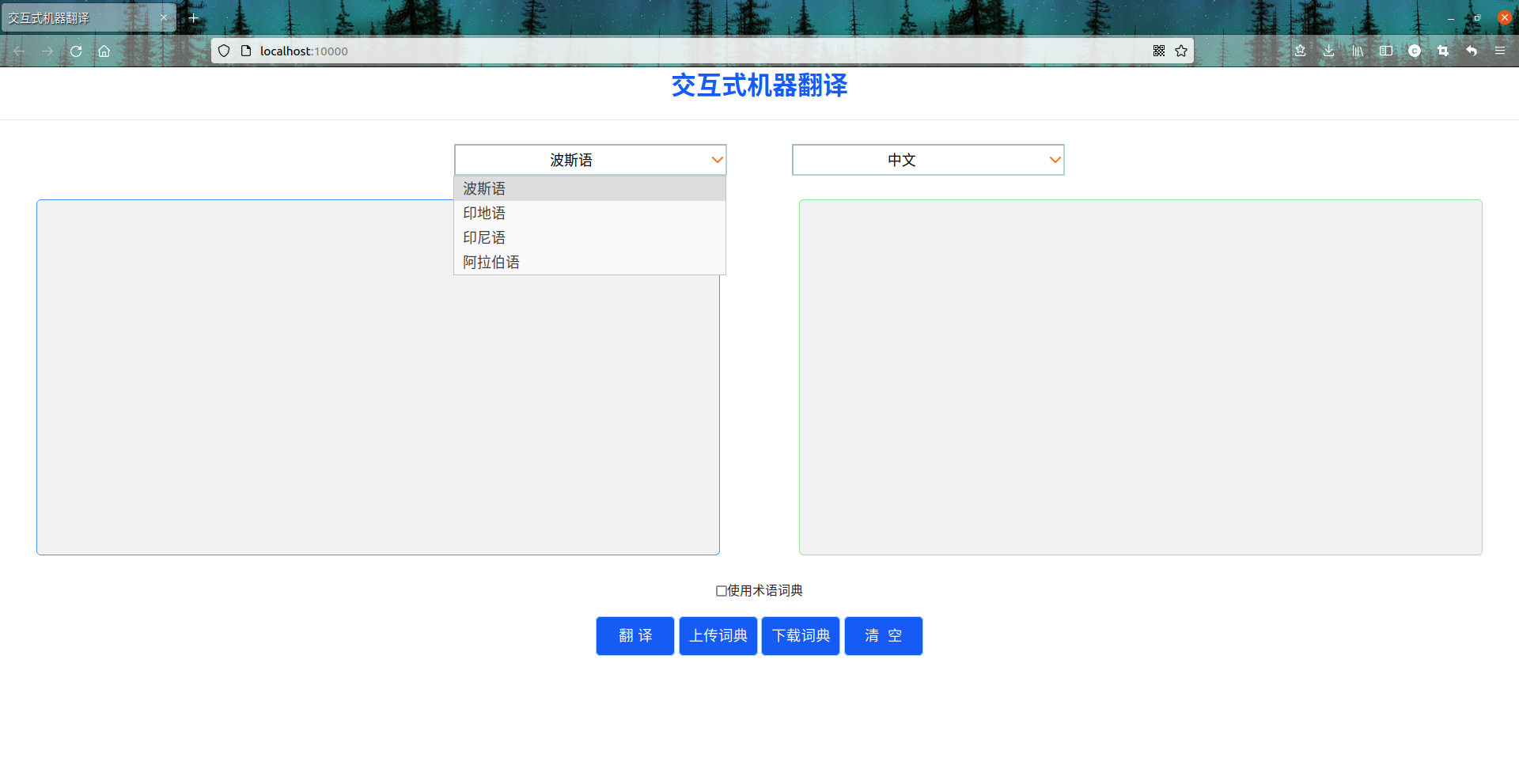
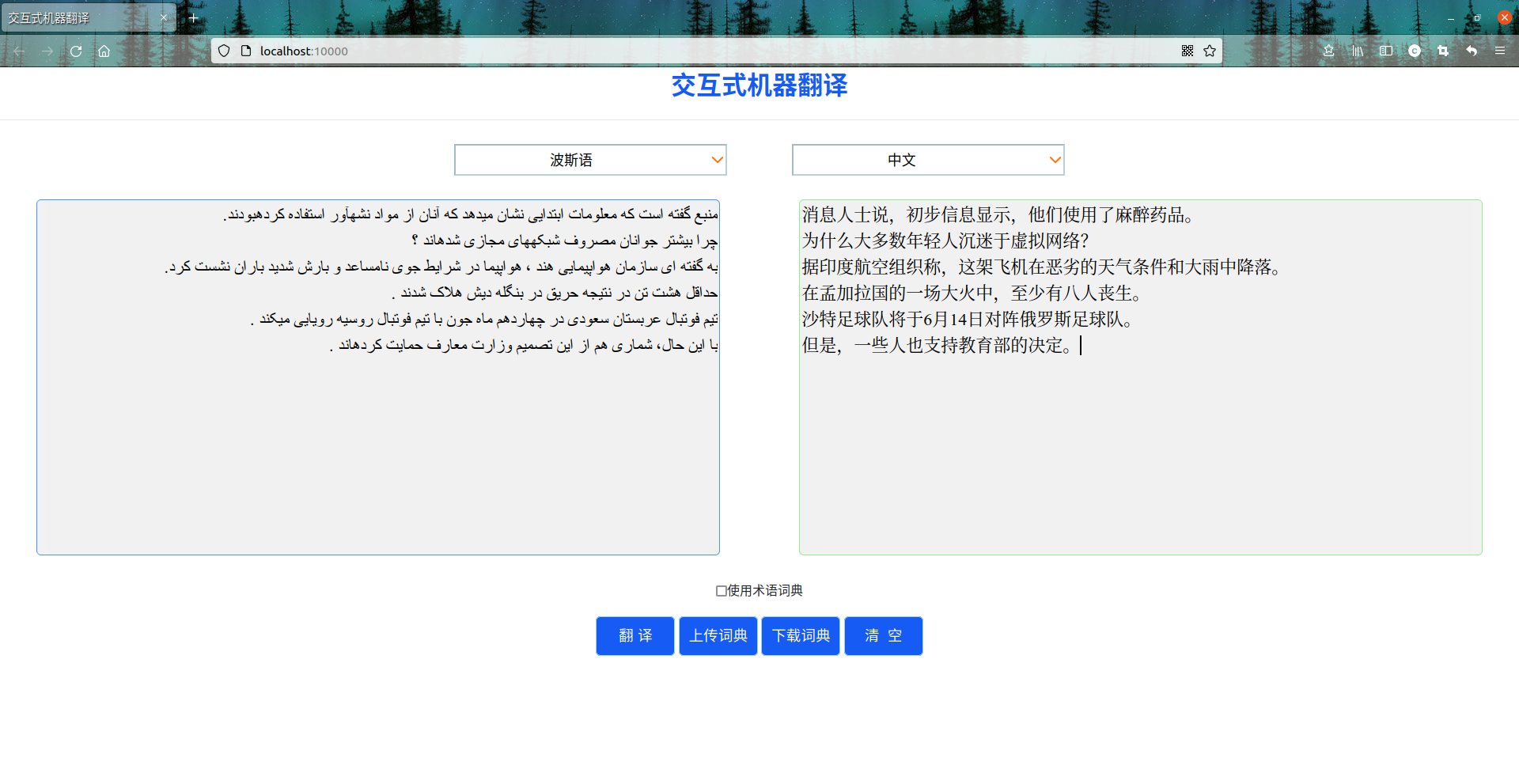
(2)波斯语翻译效果展示
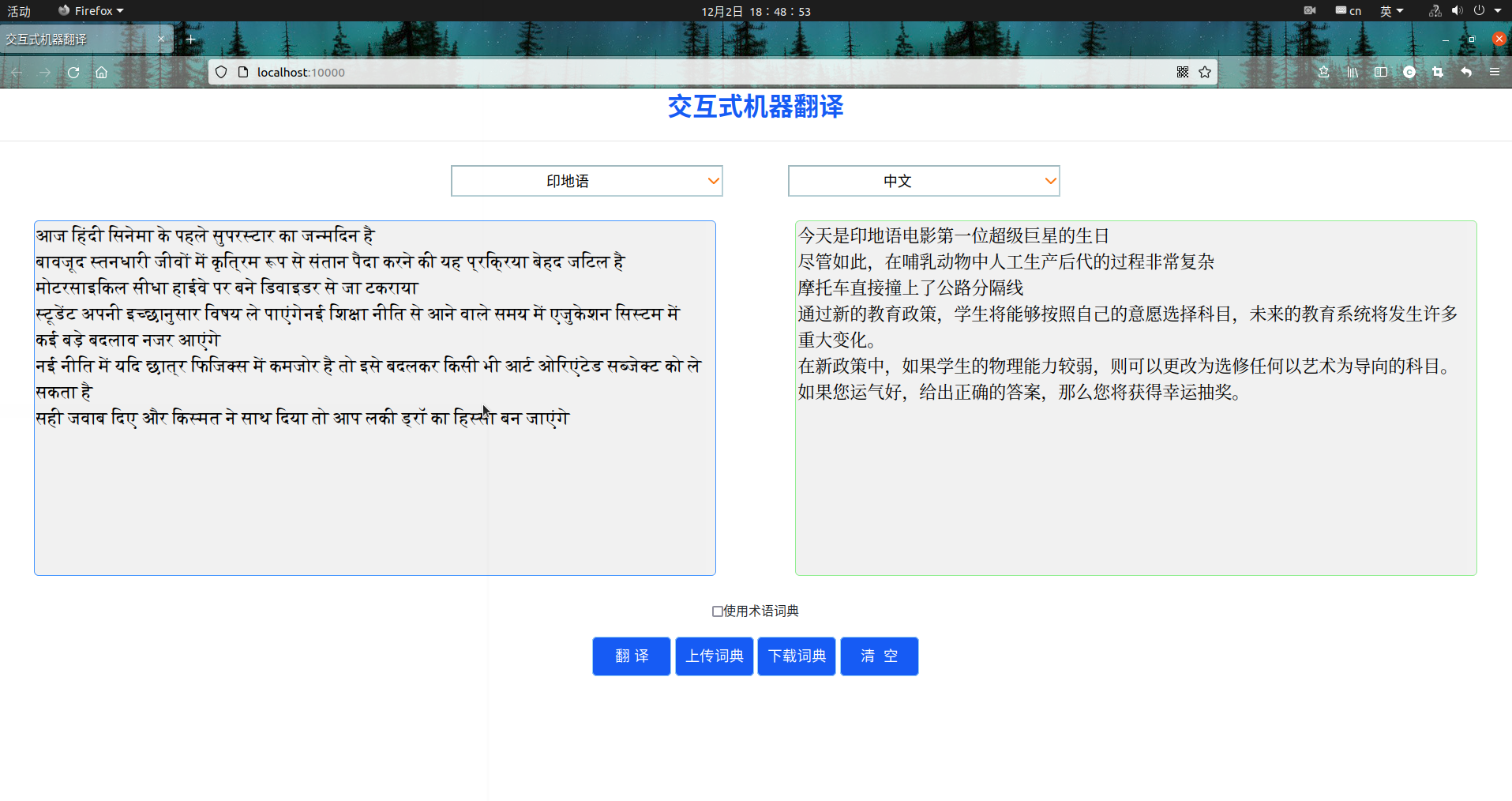
(3)印地语翻译效果展示
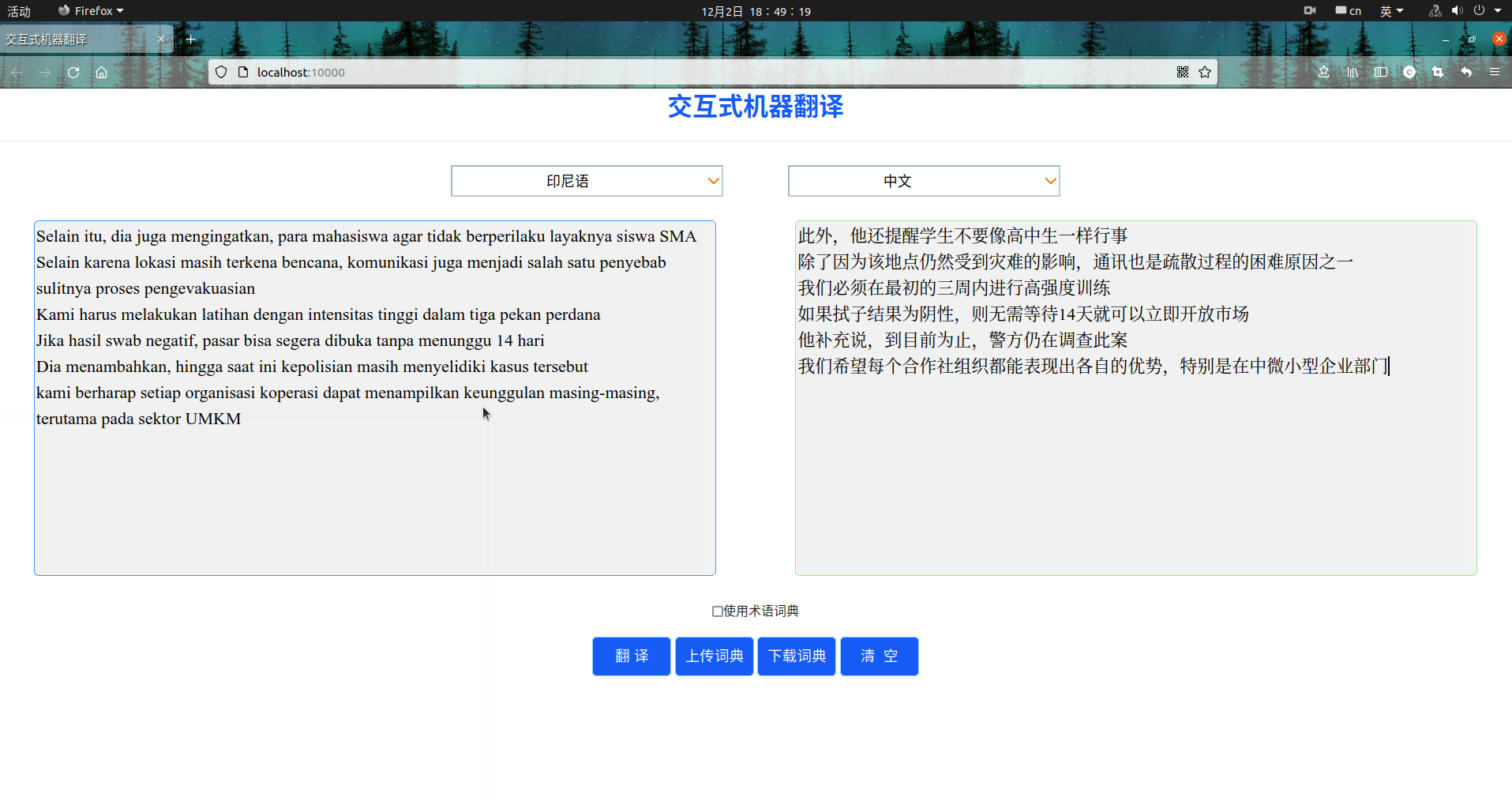
(4)印尼语翻译效果展示
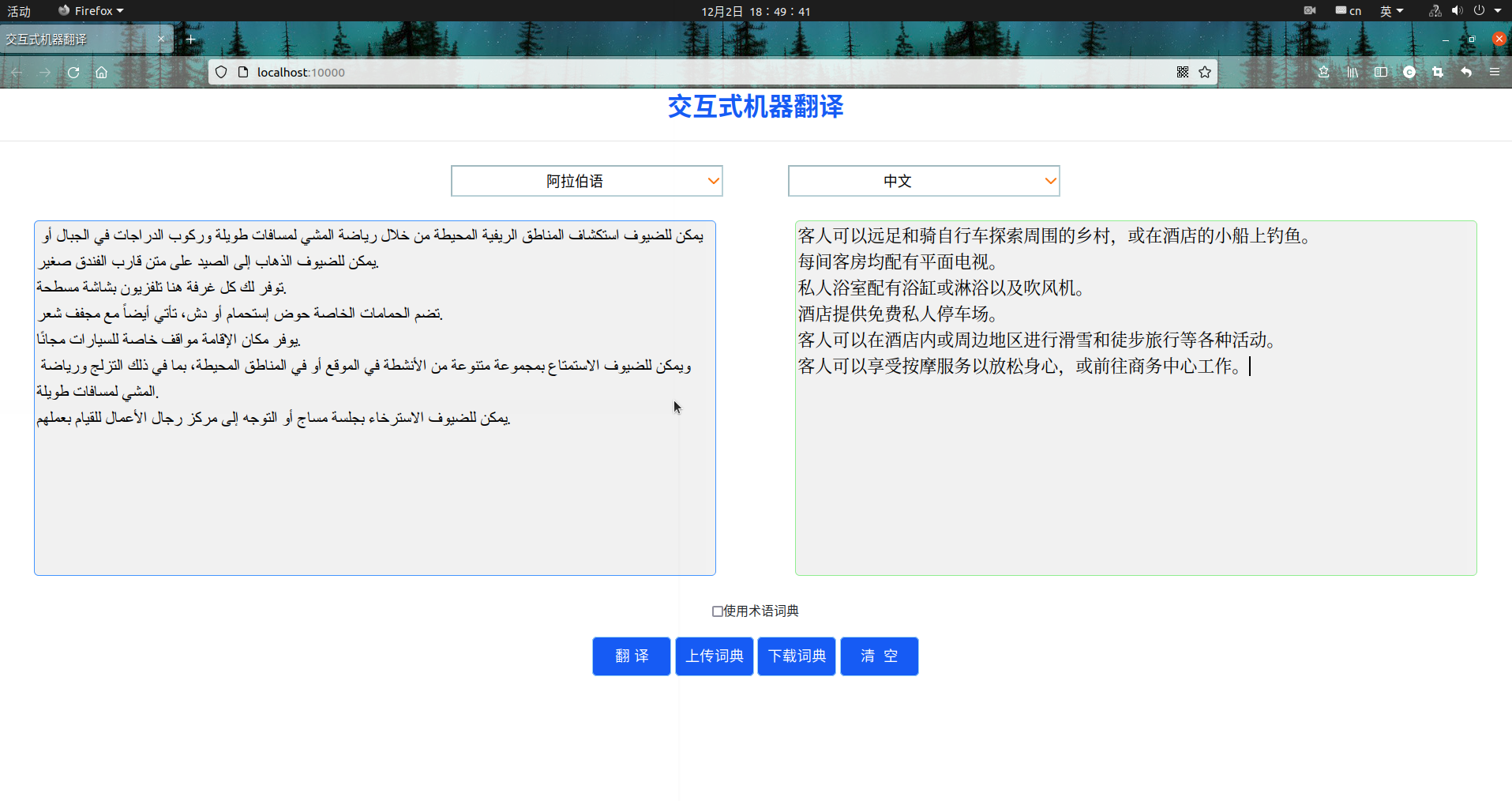
(5)阿拉伯语翻译效果展示
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢