
开放域问答需要问答系统根据文本语料直接回答自然语言问题。与机器阅读理解不同,开放域问答没有指定具体的证据,只提供了大规模的语料库。因此,问答系统需要强大的信息搜寻能力来从大型语料库中收集问题的证据,这对于答案的推理和可解释性都至关重要。目前所有方法在收集证据时都采用预定义的信息搜寻策略,要么重复地使用一种指定的检索函数,要么按照预先规划的顺序使用多种检索函数。

然而,这些预定义的信息搜寻策略无法充分发挥各类检索函数的优点、避免它们的缺点,也无法满足各样问题的多样化信息需求。下图列出了三类常用的检索函数的优缺点,对于其中第一个这种包含关键词“奥斯曼”的查询,用BM25之类的稀疏检索函数就能容易地搜索到相关证据;而对于第二个这种没有显著词并且语义关系复杂的查询,DPR之类的稠密检索函数将有机会施展其更强大的语义捕获能力;对于第三个这种带有歧义的查询,如果不利用其中的实体链接或超链接仅通过内容将会很难搜索到真正的证据。

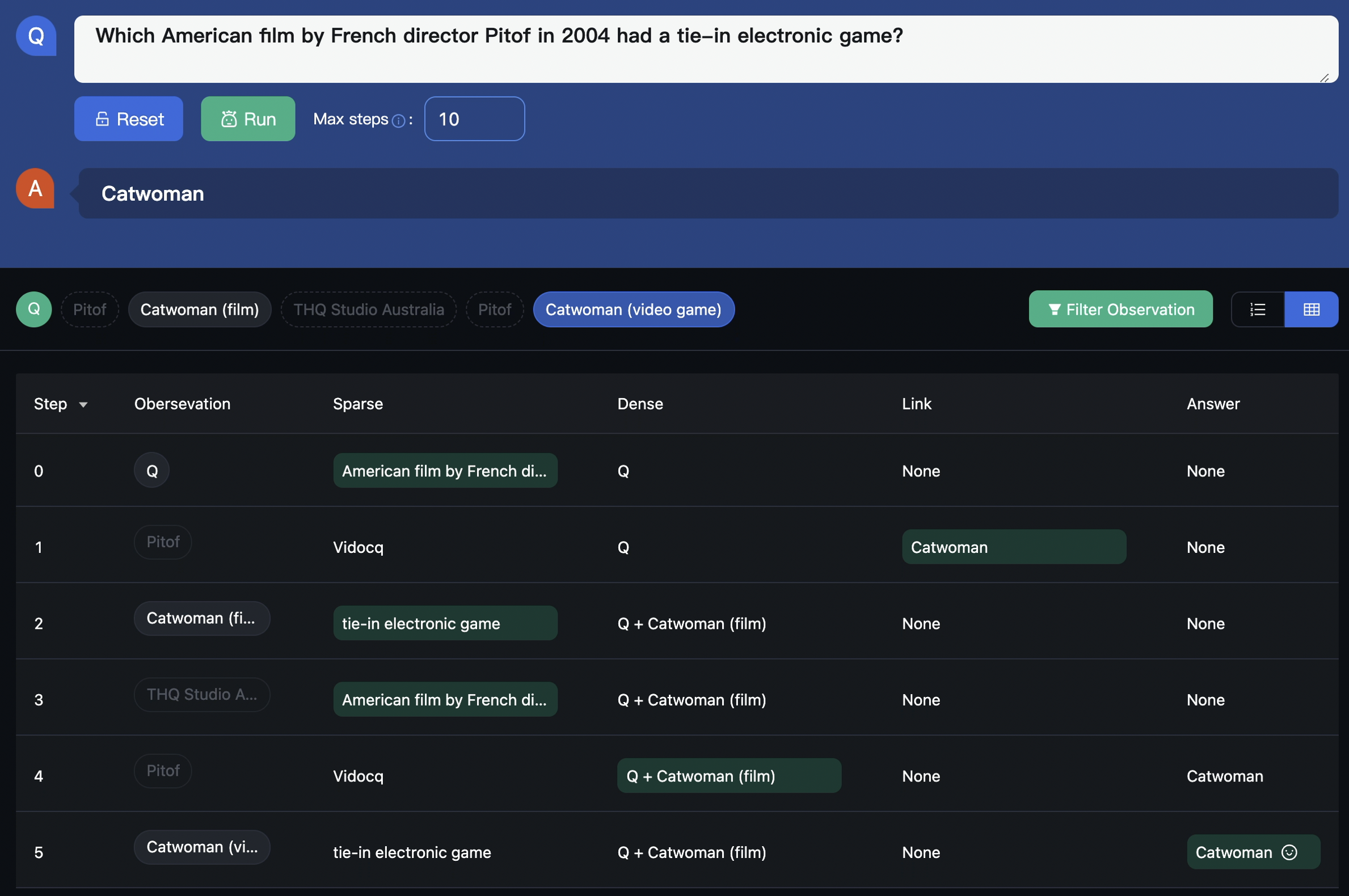
因此,在收集回答问题的证据时,我们不应按照预定义的搜寻策略使用提前指定的检索函数,而是应该采用自适应的信息搜寻策略,根据当前问题、查询等情况使用最适合当前状态的检索函数。以下面这个问题为例,这个问题问2004年法国导演皮托夫的哪部美国电影有配套的电子游戏。问题里没有超链接,并且包含了一个英文训练语料中较少出现的罕见词:Pitof。不过,现有的抽取式查询重构模型可以容易地抽取出一个包含这个关键词的简短查询(高亮部分),并且稀疏检索很擅长这种查询。因此,我们使用BM25来搜索,之后得到了介绍Pitof的段落p1。

读了p1之后,我们发现p1虽然无法回答问题,但它提供了一个重要的线索:电影catwoman满足了问题中的大多数条件,并且有一个超链接,因此我们直接点击超链接就到了p2。
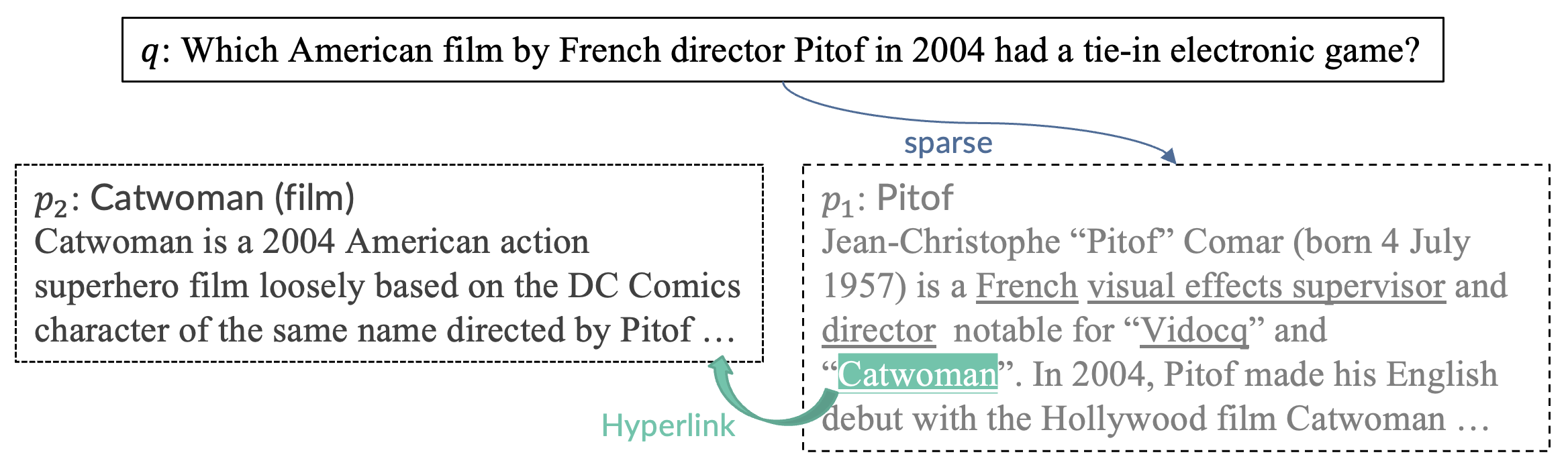
读了p2之后,我们把它看为一个候选证据,只是我们还需确认它是否有一个配套游戏。对于人类,我们可以很容易的构造出像“catwoman game”这样的查询,但现有的抽取式查询重构模型却很难为稀疏检索构造出这样理想的查询。不过幸运的是,稠密检索能够从冗长的查询中捕获语义,我们可以直接将q和p2拼起来作为查询,并用MDR进行搜索,并成功检索到了期待的段落p3。

结合问题q和证据p2、p3,我们可以最终确定电影“Catwoman”就是该问题的答案。
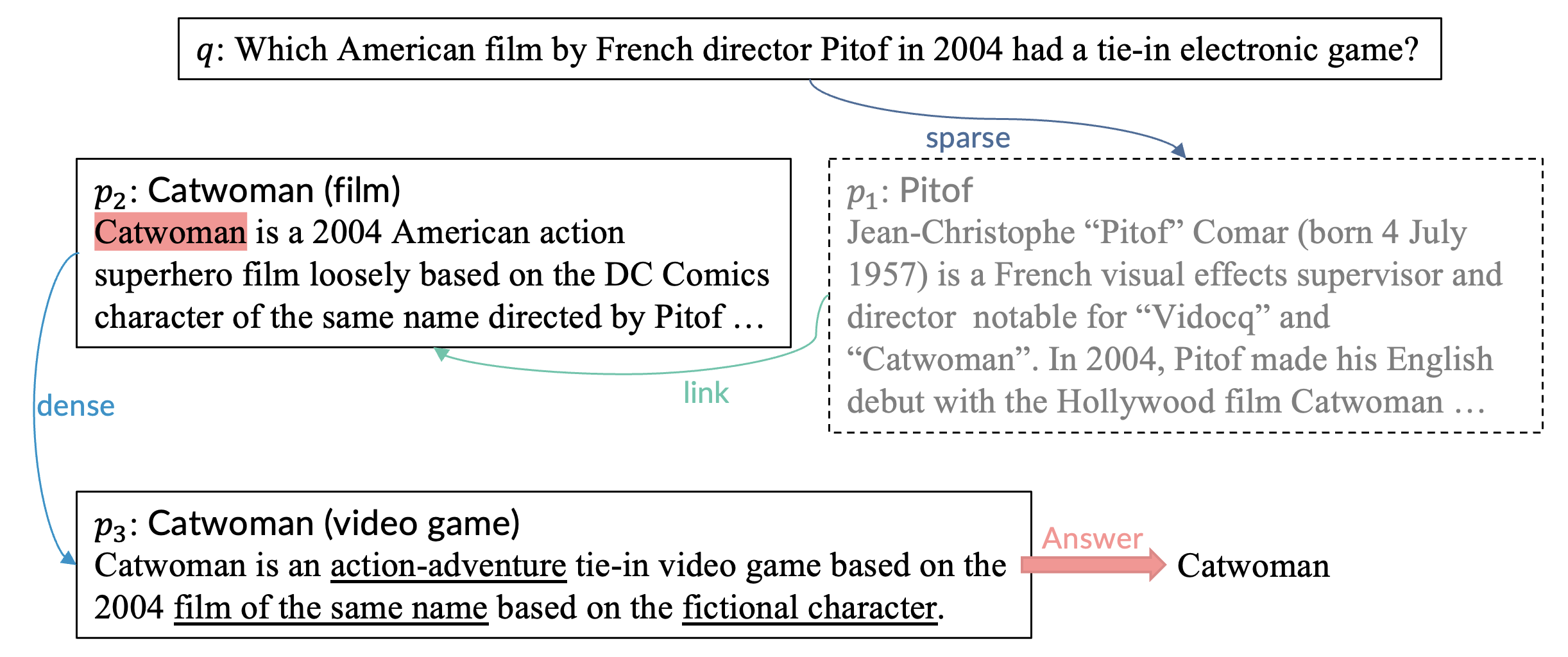
因此,对于这个问题,理想的自适应信息搜寻策略就是先稀疏检索,再链接检索,最后用稠密检索。但如何才能让问答模型找到这样一个有效的策略呢?
通过刚才的例子,我们可以发现这个迭代收集证据并回答问题的过程其实是一个序列决策问题。此外,由于语料库很大,模型每次只能观测到里面的一部分段落,我们就将开放域问答的过程建模成一个部分观测的马尔科夫决策过程(POMDP),把问答模型看作agent,并把大规模语料库放在environment当中。

其中,environment在执行action后会向agent返回一个段落作为observation。这里的每个action都是由一个可执行函数和输入到这个函数的参数组成。我们这里使用了两类函数:一类是retrieval function,它以查询为输入参数;另一类是answer function,它将参数(答案)回复给问题并结束整个过程。在收到一个retrieval action时,环境会更新这个action对应的检索列表的展示状态,并返回最顶部的未展示段落作为observation。
agent需要向environment发出action来寻求证据并回答问题,它包含两部分,首先是belief模块根据历史经历(experience)生成信念状态(belief state),之后policy模块根据当前的belief state来采取action。
为了将experience h_t,也就是observation和action的历史,转换成belief state b_t,belief模块维护了一个证据集E,我们希望这个证据集最后能包含充足的证据并且没有无关段落。在新的一步开始时,我们会用上一步更新后的证据集加上当前观测的段落构成新的候选证据集。为了简便起见,我们假设action历史和negative段落对后续决策是没有帮助的。因此,experience最终就可以等价为问题加上当前的候选证据集,也就是我们最后设计的belief state。

policy模块选择分数最大的候选action作为下个action。我们为agent配备了三种不同的retrieval function和一个answer function。为了缩减无穷的action space,我们使用参数生成器来为每个函数生成一个最合理的查询或者答案作为它的输入参数,这样候选action的数量就可以被缩减到4个。
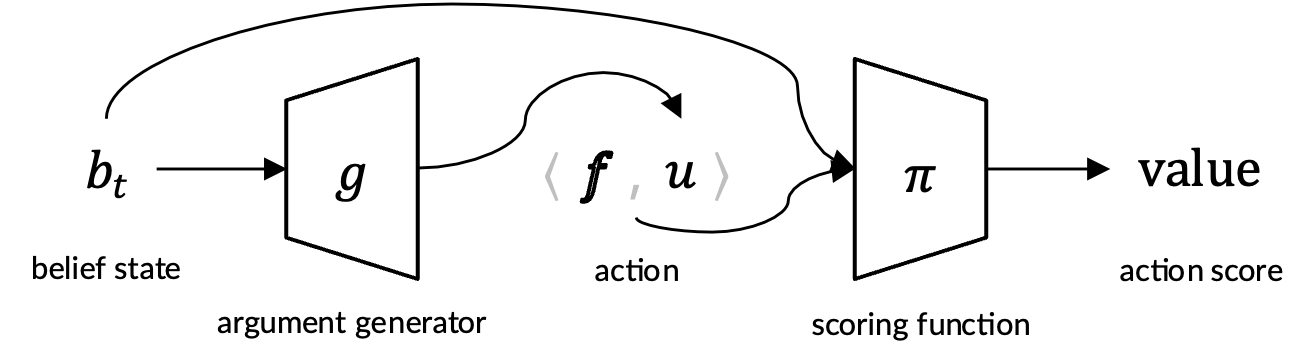
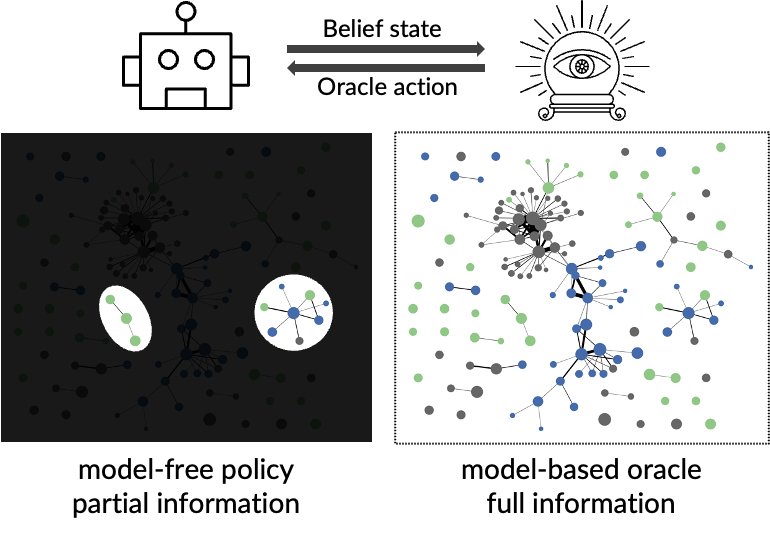
在训练时,大多数部件都可以直接利用问答数据集中的监督信号进行监督学习,或者可以直接使用现有的训练好的模型。然而对于policy模块中的action打分函数,我们构建了一个model-based oracle(能完全访问环境并可以根据贪心算法算出近似最优的action),并让agent模仿学习model-based oracle的决策。
在HotpotQA fullwiki上的检索结果表明,无论从效果还是效率上看,我们基于自适应信息寻求策略的方法都要明显好于基于预定义策略的方法。
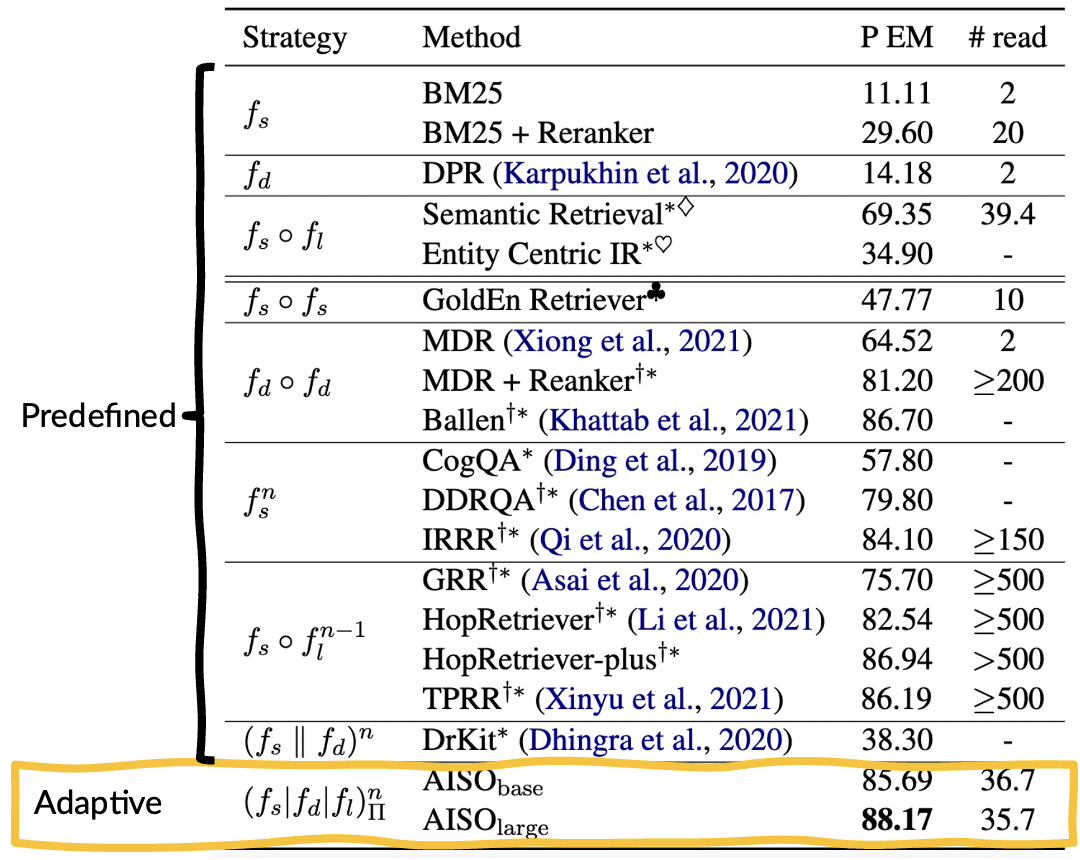
得益于高效的检索,我们的方法也取得了最先进的问答表现,取得了HotpotQA fullwiki排行榜的第一名。

最后看一下我们方法对于前面例子中的那个问题的实际表现,可以发现虽然和前面的理想的自适应策略的3步有一点点差距,但也很好很快的回答了问题。
如果大家想了解我们方法的更多细节,欢迎大家查看我们在EMNLP 2021上发表的论文Adaptive Information Seeking for Open-Domain Question Answering。我们也在GitHub开源了该方法的代码,其中包含了一个朴素版界面的demo。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢