标题:伊利诺伊大学、微软|COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining(COCO-LM:用于语言模型预训练的更正和对比文本序列)
作者:Yu Meng、Jiawei Han、Xia Song等
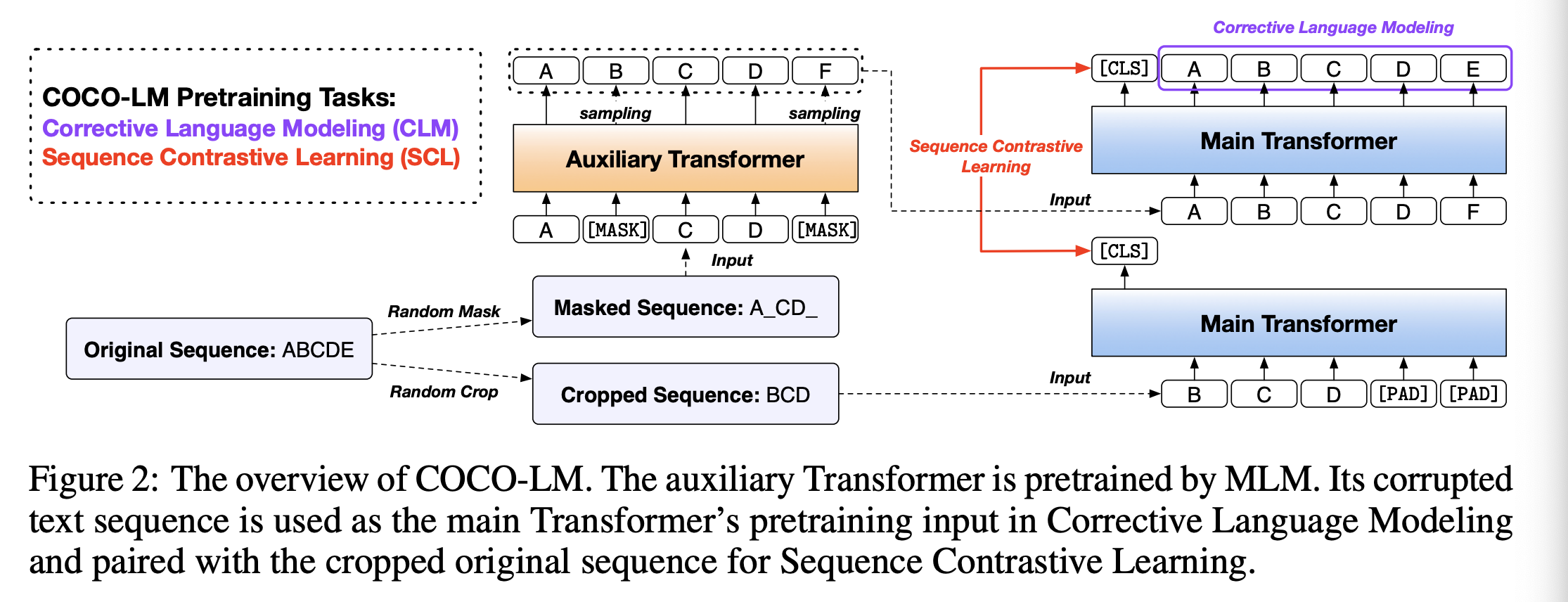
简介:本文提出了一种自然语言理解的预训练模型。作者提出了一个自监督学习框架COCO-LM,它通过纠正和对比损坏的文本序列来预训练语言模型。下列的ELECTRA 式的预训练,COCO-LM采用了辅助语言模型破坏文本序列,在此基础上构建两个新的预训练任务主要型号。第一个令牌级任务,纠正语言建模,是检测并纠正辅助模型替换的token,以便更好地捕获令牌级语义。第二个序列级任务,序列对比学习,是对齐源自相同源输入的文本序列,同时确保表示空间的一致性。在GLUE和SQuAD上的实验证明COCO-LM不仅优于最近最先进的预训练模型的准确性,也提高了预训练效率。它实现了MNLI、ELECTRA的准确率及其50%的预训练GPU小时数。在标准基础/大型模型的预训练步骤中,COCO-LM优于以前的最佳模型GLUE平均分1+分。
论文链接:https://arxiv.org/pdf/2102.08473.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢