
本文基于论文《Explore, Filter and Distill: Distilled Reinforcement Learning in Recommendation》,发表于CIKM 2021,论文作者来自微信看一看团队。

论文链接:
https://dl.acm.org/doi/abs/10.1145/3459637.3481917
强化学习(Reinforcement learning, RL)已经在真实世界的推荐系统中被广为验证。然而,基于强化学习的推荐算法常常会带来巨大的内存和时间成本。知识蒸馏(Knowledge distillation, KD)则是一种常见的有效压缩模型同时尽量保持模型有效性的方法。但是,推荐中的强化学习模型往往需要在极度稀疏的用户-物品空间中进行大规模的探索(RL exploration),而这增加了强化学习推荐模型进行蒸馏的难度。
在强化学习蒸馏中,老师(teacher)需要教给学生(student)哪些课程(例如老师对于有标签/无标签的user-item对的评分),以及学生需要从老师的课程中学习多少(即每个蒸馏样例的学习权重),需要被精细地规划和设计。在这个工作中,我们提出了一个全新的蒸馏强化学习推荐模型(Distilled reinforcement learning framework for recommendation, DRL-Rec),希望能够在压缩模型的基础上保持(甚至提升)模型的效果。
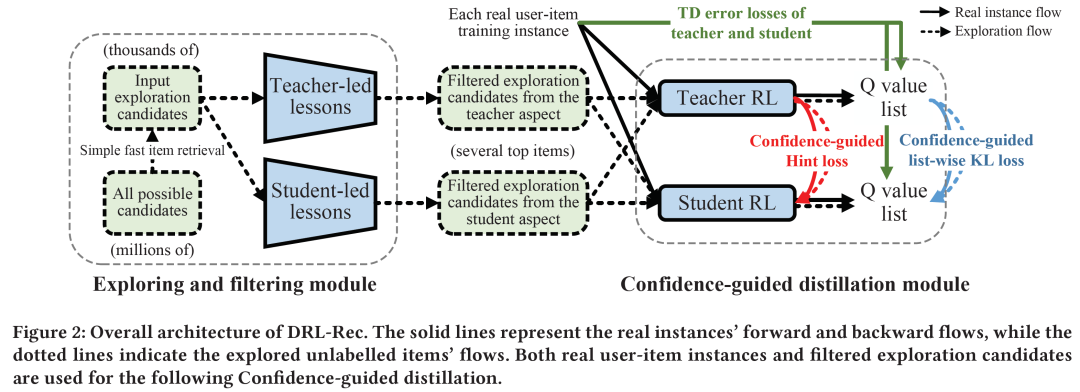
DRL-Rec主要包括三个模块:老师/学生(主推荐网络)模块(Teacher and student module),探索/过滤模块(Exploring and filtering module),置信度引导的蒸馏模块(Confidence-guided distillation)。
模型的贡献点如下:
■ 我们提出了一个全新的DRL-Rec框架,关注推荐强化学习模型的蒸馏问题。据我们所知,这是第一个在推荐系统中考虑强化学习模型之间的知识蒸馏的方法;
■ 我们提出了一个探索/过滤模块,通过双向主导的学习机制,从teacher和student两个角度预先筛选高信息量的item进行蒸馏,解决了teacher在百万item候选中的“what to teach”的问题;
■ 我们还提出一个置信度引导的蒸馏模块,在list-wise推荐定制的list-wise KL divergence loss和Hint loss上引入置信度的概念,帮助student更关注teacher更擅长的、把握更大的知识;
■ DRL-Rec模型在离线和线上都取得了显著的效果和效率提升,并已部署于微信看一看推荐系统,服务千万用户。
目前,DRL-Rec模型目前已经部署于微信看一看系统,服务千万用户。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢