
自从Google石破天惊地发布Bert以来,NLP就进入了预训练语言模型的时代。众所周知,我们可以用预训练语言模型来学习各种各样的任务,即使它们的特征空间有比较大的差异。那么预训练语言模型为什么会有这种泛化能力呢?或者说预训练阶段学习到的通用表示为什么可以很容易地适应广泛的下游NLP任务呢?
本文介绍的这篇文章从近来大火的 prompt tuning 的角度出发, 对这个问题进行了初步的探索。它经验性地发现:预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征子空间(common low-dimensional intrinsic task subspace)中非常少量的几个自由参数。为了证明这一观点,作者在100多个 few-shot 任务上进行了实验,发现仅仅优化子空间中的 5个自由参数,就可以获得 full prompt tuning 87% 的性能。
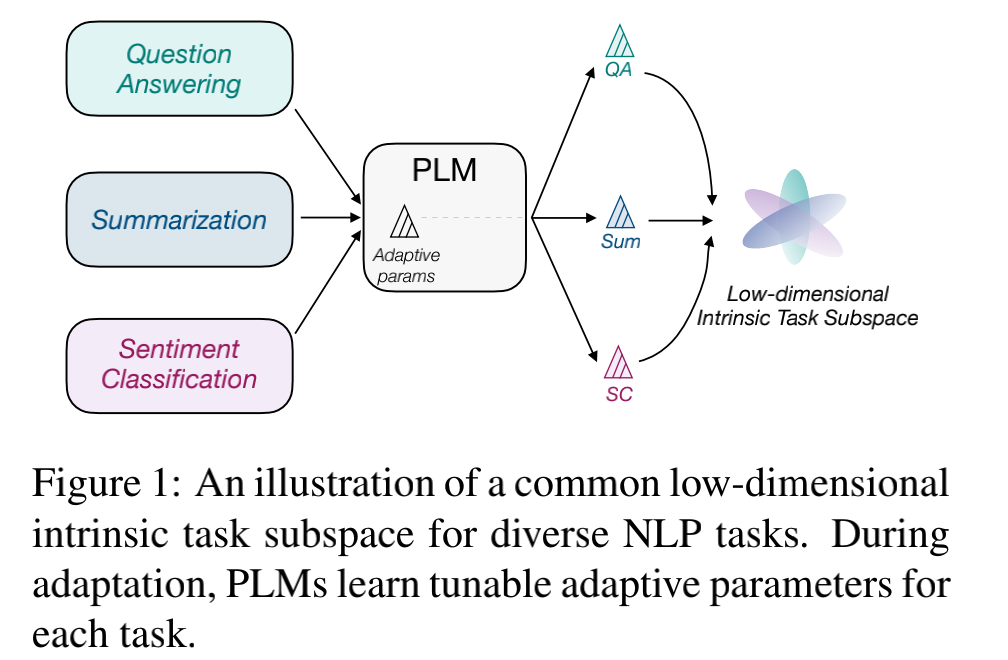
至于,何为“任务的公共低维本征子空间”?作者又是如何论证得到上述结论的?在下文中我们将为大家仔细解读。
论文标题:
Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning
论文链接:
https://arxiv.org/pdf/2110.07867.pdf
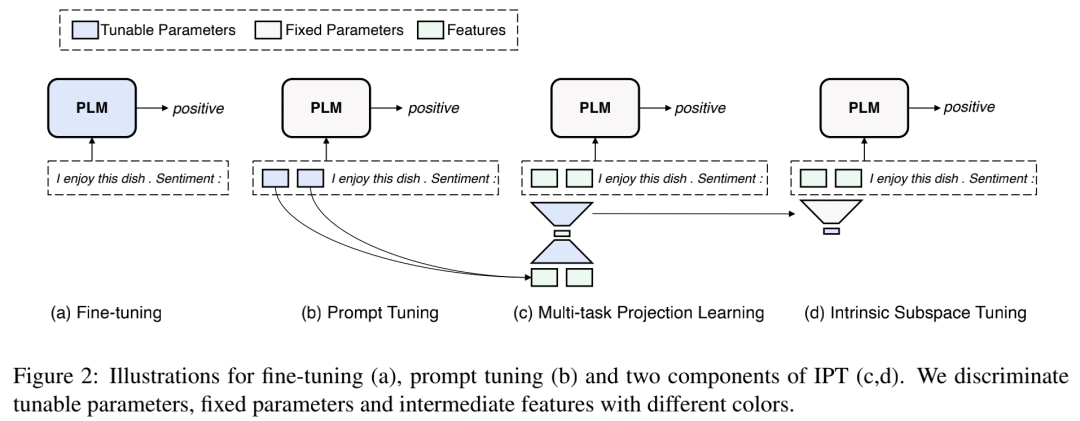
作者提出了探索公共低维本征子空间的方法: intrinsic prompt tuning (IPT) 。
IPT由两个阶段组成:
-
Multi-task Subspace Finding (MSF):寻找多个任务的公共子空间,这是一个低维的、更为本征的一个空间
-
Intrinsic Subspace Tuning (IST):在找到的公共本征子空间上进行模型优化
下图展示了 IPT 与 fine-tuning 和 prompt tuning 的对比。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢