
近年来,SE(3) 等变网络在 3D 语义分析任务中发挥着重要的作用,尤以 3D 姿态可控卷积神经网络为代表。3D 姿态可控卷积神经网络利用姿态可控卷积(ST-Conv)逐层学习姿态等变的特征,从而保留 3D 输入的姿态信息。为了生成姿态可控特征,ST-Conv 将特征域限定在 3D 体素数据的规则网格上,使其能通过 3D 卷积方便地实现。对 3D 卷积的兼容简化了 ST-Conv 的实现,但也牺牲了对不规则且稀疏的 3D 数据(例如,点云)的高效处理,导致 ST-Conv 未能在更多 3D 语义分析领域中被广泛使用。
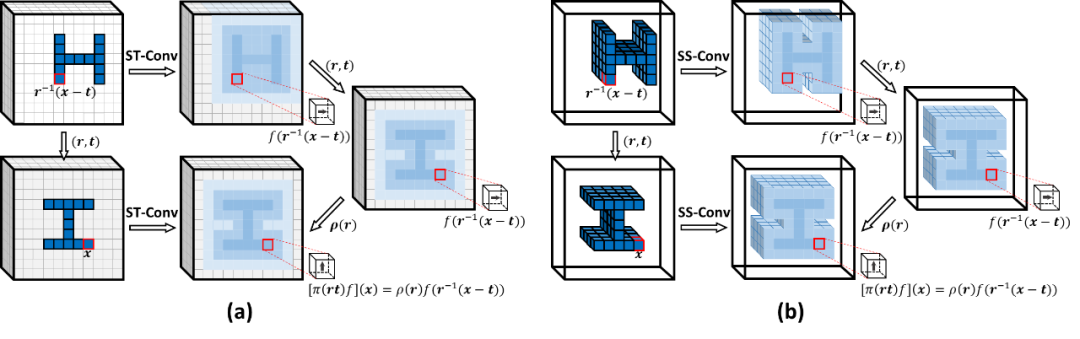
图 1. SE(3) 等变性:(a)ST-Conv;(b)SS-Conv。箭头表示 3D 场中有向的特征向量。
为了解决上述问题,华南理工大学等研究人员提出了一个新颖的稀疏姿态可控卷积(SS-Conv)。SS-Conv 不仅利用稀疏张量对姿态可控卷积进行极大地加速,还在特征学习中严格地保持 SE(3) 等变性。图 1(b) 对 SS-Conv 的 SE(3) 等变特性进行了阐释。为了实现 SS-Conv,研究人员通过基于球形谐波的基核的线性组合来建立卷积核,使其满足 SE(3) 等变卷积应遵循的旋转可控约束条件,同时基于稀疏张量在激活的特征位置上利用 GPU 上的矩阵加乘操作实现快速卷积。

论文链接:
https://arxiv.org/abs/2111.07383
代码链接:
https://github.com/Gorilla-Lab-SCUT/SS-Conv
虽然 SE(3) 等变特征学习在 3D 物体识别任务上被广泛使用,其潜能在 3D 语义分析的其他任务上却尚待开发。研究人员尝试将 SS-Conv 应用到 3D 空间中物体姿态估计中,因此提出了一个基于 SS-Conv 的通用框架,通过堆叠多层 SS-Conv 来提取 SE(3) 等变特征,从而直接解码出物体的姿态。在这个框架中,一个新颖的特征操控模块(Feature-Steering module)充分地利用特征的可控性来迭代地对姿态进行优化。研究人员在三个姿态相关的 3D 物体语义分析任务上进行充分的实验,包括实例层级的 6D 物体姿态估计、类别层级的 6D 物体姿态及大小估计、类别层级的 6D 物体姿态跟踪。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢