
作者:Rui Wang, Dongdong Chen, Zuxuan Wu,等
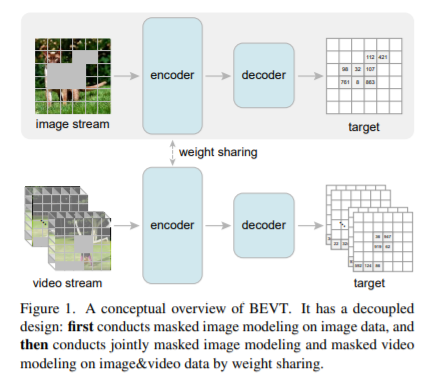
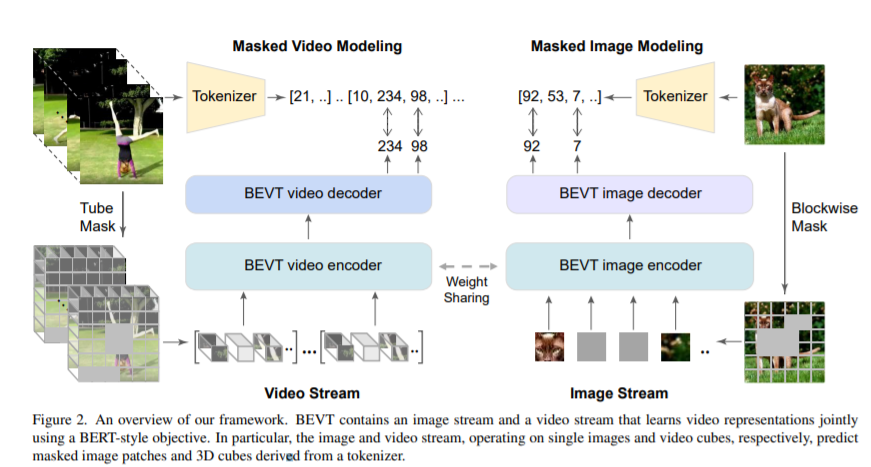
简介:本文研究了视频转换器的BERT预训练。鉴于 BERT 图像变换器预训练最近取得的成功,这是一个简单但值得研究的扩展。作者引入了 BEVT,它将视频表示学习解耦为空间表示学习和时间动态学习。特别地,BEVT首先对图像数据进行掩码图像建模,然后结合掩码视频建模对视频数据进行掩码图像建模。这种设计受到两个观察的启发:1)在图像数据集上学习的变换器提供了不错的空间先验,可以简化视频变换器的学习,如果从头开始训练,视频变换器通常是计算密集型的;2)判别线索,即空间和时间信息,由于大的类内和类间变化,不同视频之间需要做出正确的预测。作者对三个具有挑战性的视频基准进行了广泛的实验,其中 BEVT 取得了非常有希望的结果。在 Kinetics 400 上,其识别主要依赖于区分性空间表示,BEVT 实现了与强监督基线相当的结果。在包含依赖时间动态的视频的Something-Something-V2 和Diving 48 上,BEVT 的表现明显优于所有替代基线,并分别以 70.6% 和 86.7% 的 Top-1 准确率实现了最先进的性能。对于识别主要依赖于区分性空间表示,BEVT 实现了与强监督基线相当的结果。在包含依赖时间动态的视频的Something-Something-V2 和Diving 48 上,BEVT 的表现明显优于所有替代基线,并分别以 70.6% 和 86.7% 的 Top-1 准确率实现了最先进的性能。对于识别主要依赖于区分性空间表示,BEVT 实现了与强监督基线相当的结果。在包含依赖时间动态的视频的Something-Something-V2 和Diving 48 上,BEVT 的表现明显优于所有替代基线,并分别以 70.6% 和 86.7% 的 Top-1 准确率实现了最先进的性能。
论文下载:https://arxiv.org/pdf/2112.01529.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢