
【标题】Sample Complexity of Robust Reinforcement Learning with a Generative Model
【作者团队】Kishan Panaganti, Dileep Kalathil
【发表日期】2021.12.3
【论文链接】https://arxiv.org/pdf/2112.01506v2.pdf
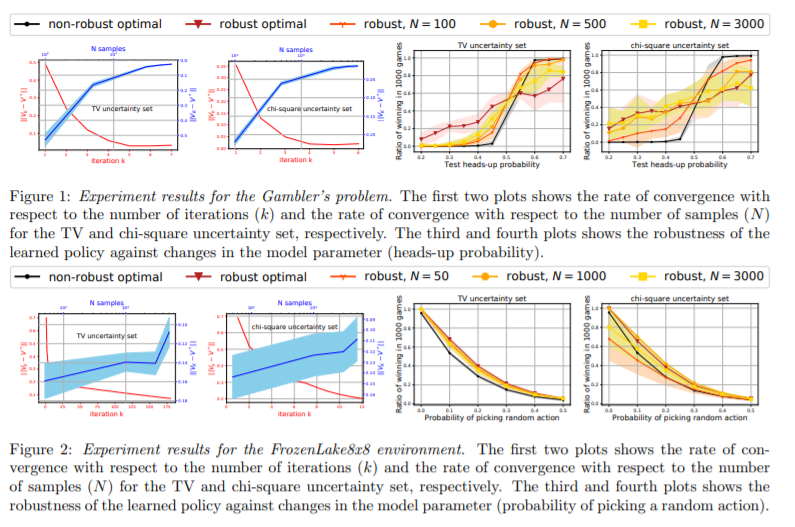
【推荐理由】鲁棒马尔可夫决策过程 (RMDP) 框架侧重于设计控制策略,这些策略对于由于模拟器模型与现实世界设置之间的不匹配而导致的参数不确定性具有鲁棒性。RMDP 问题通常被表述为最大-最小问题,其中目标是找到最大化最坏可能模型的价值函数的策略,该模型位于围绕标称模型的不确定性集中。标准的鲁棒动态规划方法需要知道用于计算最优鲁棒策略的标称模型。本文提出了一种基于模型的强化学习 (RL) 算法,用于学习ε- 名义模型未知时的最优稳健策略。通过考虑三种不同形式的不确定性集,以总变异距离、卡方散度和 KL 散度为特征。对于这些不确定性集合中的每一个,研究表明本文提出的算法的样本复杂性的精确表征。除了样本复杂性结果之外,还提出了关于使用稳健策略的好处的正式分析论点。最后,研究展示了该算法在两个基准问题上的优越性能。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢