
图分类(Graph Classification)是指预测输入图的类别标签的任务,它已被广泛应用于各种图数据,包括分子结构、生物网络和社交网络。
图分类的关键的挑战是从拓扑结构(即节点和边)和辅助节点特征中提取信息(或判别性)图特征。
今天分享一些最近的关于图分类问题的相关研究
1.【ICDM2021】Learnable Structural Semantic Readout for Graph Classification\
地址: https://arxiv.org/abs/2111.11523
导读:
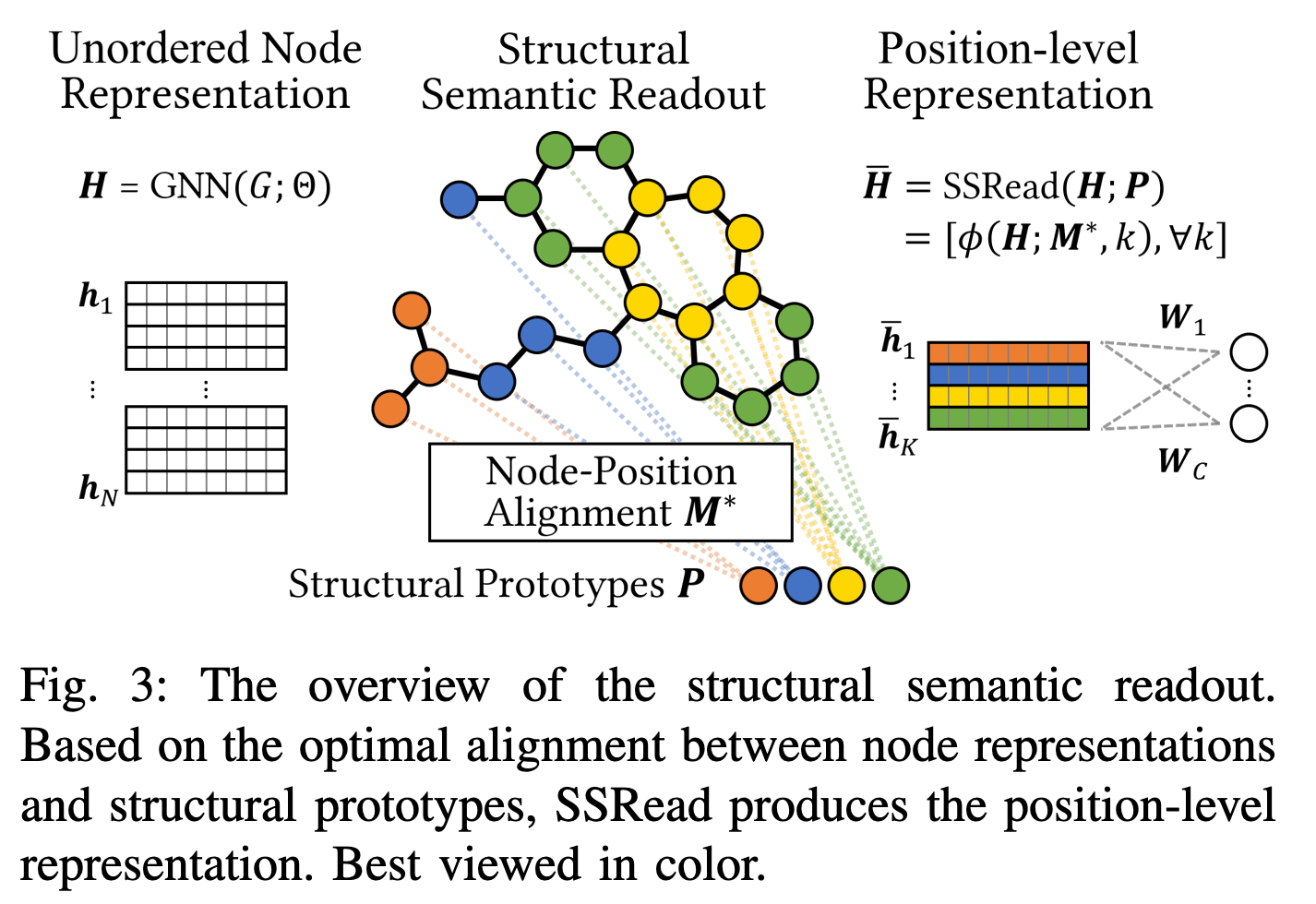
随着深度学习在各个领域的巨大成功,图神经网络 (GNN) 也成为图分类的主要方法。通过简单地聚合所有节点(或节点集群)表示的全局读出操作,现有的 GNN 分类器获得输入图的图级表示,并使用该表示预测其类标签。但是,这种全局聚合没有考虑每个节点的结构信息,导致全局结构上的信息丢失。特别是,它通过对所有节点表示强制使用相同的分类器权重参数来限制区分能力;在实践中,它们中的每一个都根据其结构语义对目标类做出不同的贡献。在这项工作中,作者提出了结构语义读出(SSRead)来总结位置级别的节点表示,这允许对特定位置的权重参数进行建模以进行分类,并有效地捕获与全局结构相关的图语义。给定一个输入图,SSRead 旨在通过使用其节点和结构原型之间的语义对齐来识别结构上有意义的位置,结构原型对每个位置的原型特征进行编码。优化结构原型以最小化所有训练图的对齐成本,同时训练其他 GNN 参数以预测类别标签。实验结果表明,SSRead 显着提高了 GNN 分类器的分类性能和可解释性,同时兼容各种聚合函数、GNN 架构和学习框架。
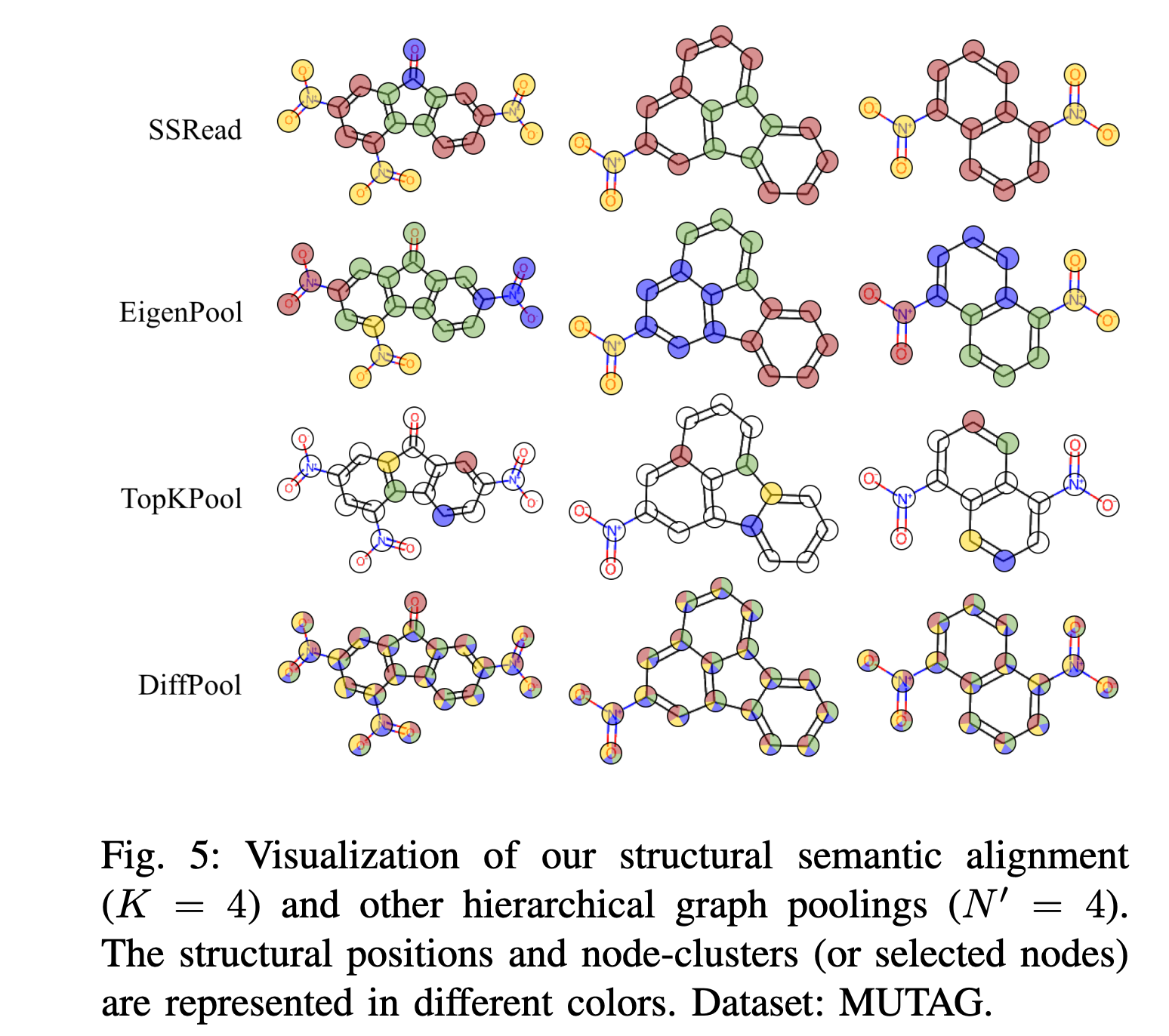
文章的图5的可视化非常的有趣,表明了其模型能够学习到结构原型。
2.【NeurIPS2021】Motif-based Graph Self-Supervised Learning for Molecular Property Prediction
地址:https://arxiv.org/abs/2110.00987
导读:
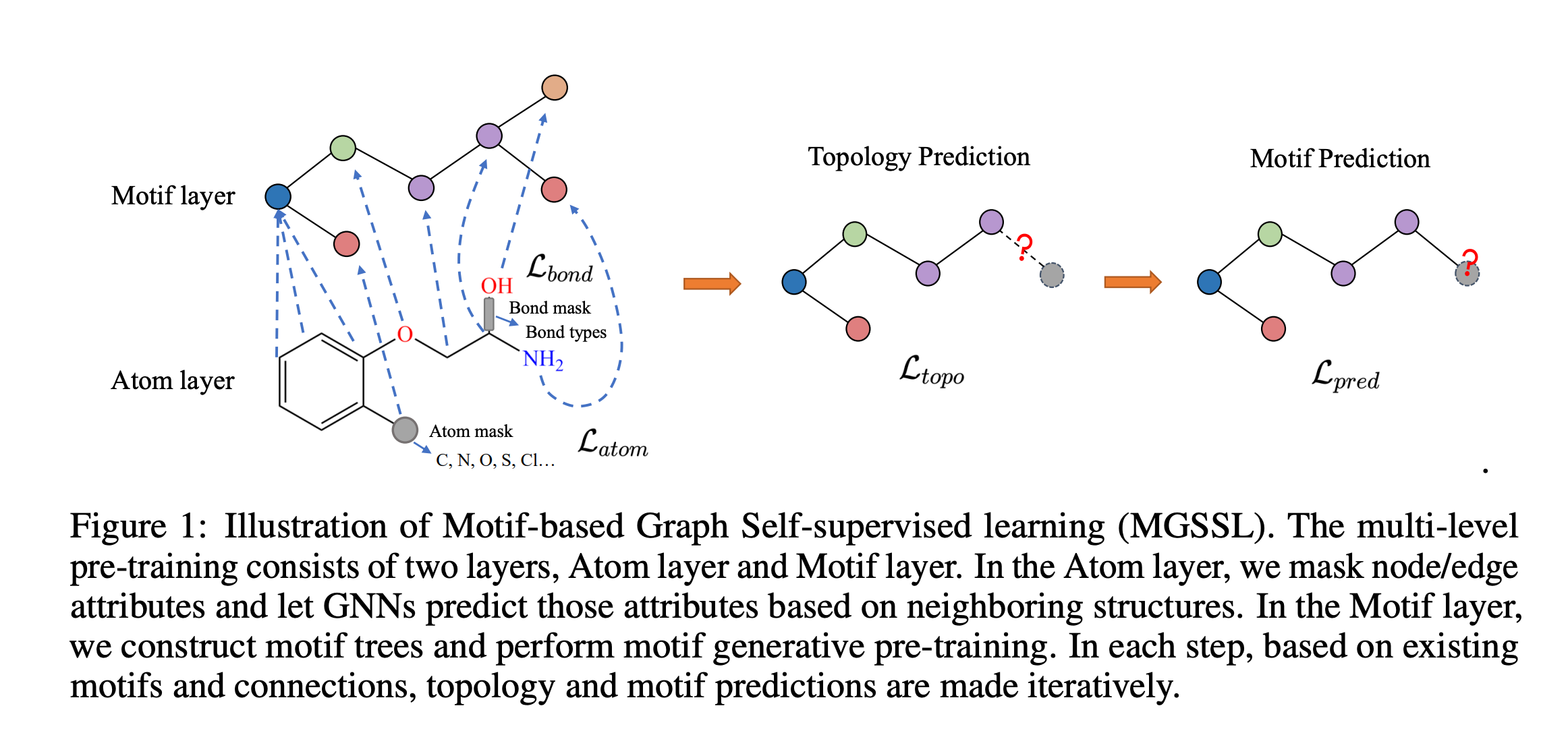
近年来,使用数据驱动的方法预测分子特性引起了广泛关注。特别是,图神经网络 (GNN) 在各种分子生成和预测任务中取得了显着的成功。在标记数据稀缺的情况下,GNN 可以在未标记的分子数据上进行预训练,以在针对特定任务进行微调之前首先学习一般语义和结构信息。然而,大多数现有的 GNN 自我监督预训练框架只关注节点级或图级任务。这些方法无法捕获子图或图主题中的丰富信息。例如,官能团(分子图中经常出现的子图)通常携带有关分子特性的指示性信息。为了弥合这一差距,文章通过为 GNN 引入一种新颖的自监督模体生成框架,提出了基于模体的图自监督学习 (MGSSL)。首先,为了从分子图中提取基序,文章设计了一种分子碎片化方法,该方法利用基于逆合成的算法 BRICS 和控制基序词汇大小的附加规则。其次,文章还设计了一个通用的基于模体的生成预训练框架,其中要求 GNN 进行拓扑和标签预测。这个生成框架可以通过两种不同的方式实现,即广度优先或深度优先。最后,为了考虑分子图中的多尺度信息,引入了多级自监督预训练。对各种下游基准任务的大量实验表明,文章提出的方法方法优于所有比较方法。
3. 【Arxiv】Imbalanced Graph Classification via Graph-of-Graph Neural Networks
导读:
在图分类任务上,存在数据不平衡的情况(某些类别的标签比其他类别少得多)。
在不平衡的数据上直接训练 GNN 可能会导致少数类图的无信息表示,并影响下游分类的整体性能。
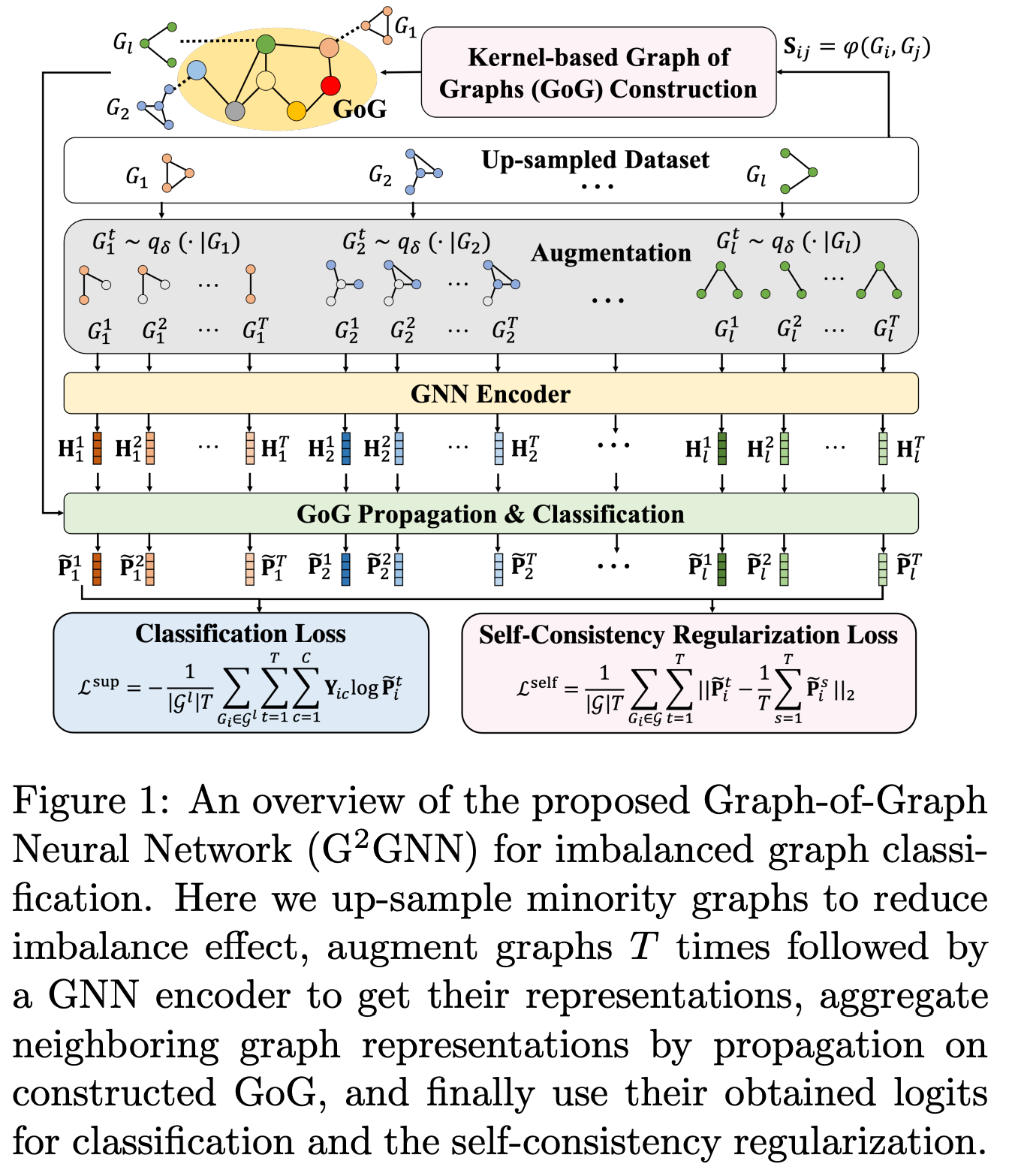
文章致力于开发有效的 GNN 来处理不平衡图分类的重要性。文章引入了一个新的框架,Graph-of-Graph Neural Networks (G2GNN),通过从相邻图全局和局部从图本身获得额外监督来缓解图不平衡问题。
在全局上,基于内核相似性构建了一个“图的图”(GoG),并执行 GoG 传播以聚合相邻图表示,这些表示是通过节点级传播通过 GNN 编码器池化获得的。
在局部上,通过屏蔽节点或丢弃边来使用拓扑增强来提高模型在识别未知测试图的拓扑方面的通用性,即一个自监督的任务。
在七个基准数据集上进行的广泛的图分类实验表明,文章提出的 G2GNN 在 F1-macro 和 F1-micro 分数中比许多基线高出大约 5%。
文章构建的“图的图”是一个非常有趣的概念, 进而通过消息传播化解类别不平衡是一个不错的主意。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢