
今年年初OpenAI的CLIP将图像和文本通过对比学习的方法联系起来,并且Zero-Shot的效果堪比ResNet50。最近几天Google Research刚出的ViLD将CLIP应用到了检测任务上,在新增类别上Zero-Shot超过Supervised的方法。难道Zero-Shot又要开始了。
本文首先介绍一下什么是Zero-Shot Learning,然后回顾一下在分类任务上取得非常好效果的CLIP,最后详细解读一下在检测任务上超越之前Supervised方法的ViLD。最后提出我的一点疑问。
对比学习相关的可以先看一下我之前的笔记。
何恺明+Ross Girshick:深入探究无监督时空表征学习
Zero-Shot Learning
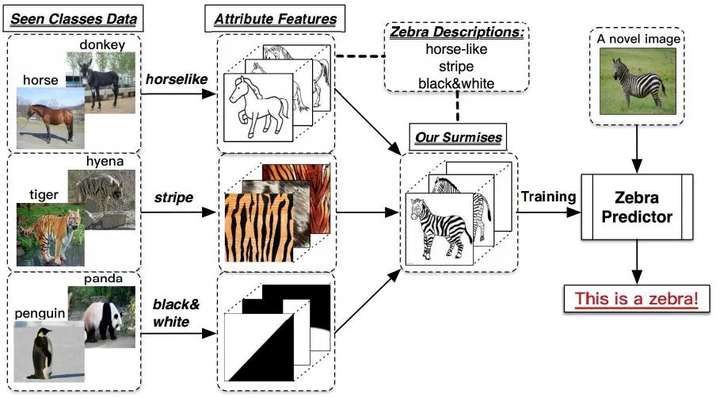
以上图为例,最左边一列是训练集图片,最右边一列的斑马是测试集的图片,并且训练集类别和测试集类别不重合,测试集图片就是没有见过的图片(即Zero-Shot)。zero-shot learning要做的事情就是从训练集图片中学习出一些属性,比如上图学到的horselike、stripe和block&white,然后将这些属性相结合得到融合特征,融合特征刚好和测试集的斑马特征相匹配,最终得到预测结果为斑马。这个过程就是zero-shot learning,用见过的图片特征去判断没见过的图片的类别。
CLIP
OpenAI从网络收集了4亿数据量的图片文本对用于CLIP训练,最后进行zero-shot transfer到下游任务达到了非常好的效果。
简单回顾一下CLIP的使用流程:
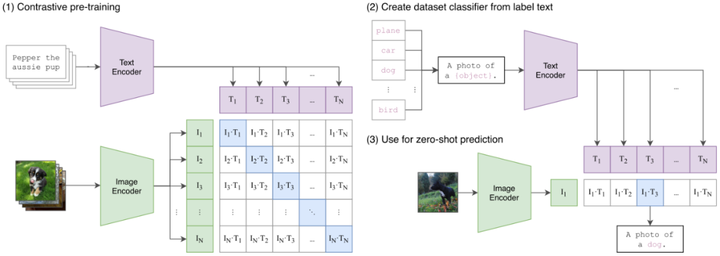
1.如图(1)所示,CLIP将一批文本通过Text Encoder编码成一批word embedding,将一批图片(与文本一一对应)通过Image Encoder编码成一批feature embedding,然后将对应的word embedding和feature embedding先归一化然后进行点积得到相似度矩阵,点积数值越大,代表word embedding和feature embedding的向量越相似,这里的监督信号就是矩阵对角线为1,其余位置为0。其中Text Encoder使用的是Transformer,而Image Encoder使用ResNet50和ViT两种架构其中一个,Image Encoder和Text Encoder都是从头训练。
2.然后将预训练好的CLIP迁移到下游任务,如图(2)所示,先将下游任务的标签构建为一批带标签的文本(例如 A photo of a {plane}),然后经过Text Encoder编码成一批相应的word embedding。
3.最后将没有见过的图片进行zero-shot预测,如图(3)所示,通过Image Encoder将一张小狗的图片编码成一个feature embedding,然后跟(2)编码的一批word embedding先归一化然后进行点积,最后得到的logits中数值最大的位置对应的标签即为最终预测结果。
对于CLIP,我的想法是对比学习使得word embedding和feature embedding学习到了对应的映射关系,可以相互表示。
ViLD
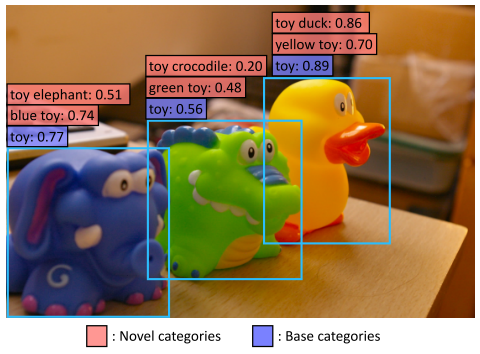
上图是一个zero-shot检测器的例子。在基础类别(紫色)上训练ViLD之后,我们可以使用新增类别(粉红色)的文本嵌入来检测训练数据集中不存在的新增类别。
Overview
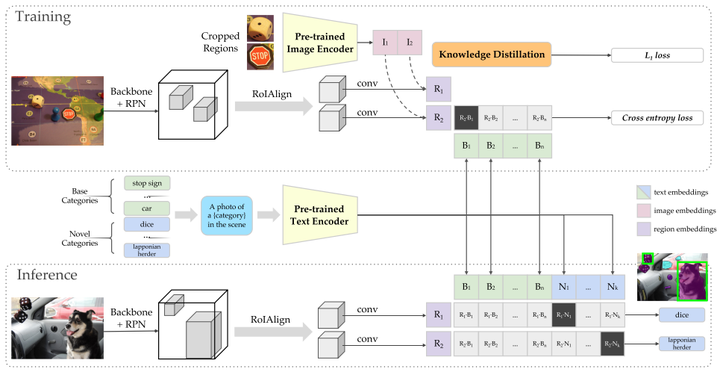
首先看一下ViLD的整体设计,后面再讲细节设计。其中Pre-trained Image Encoder和Pre-trained Text Encoder是CLIP预训练得到的。
训练阶段
先将图片标注区域的图片裁剪出来通过Pre-trained Image Encoder编码得到标注区域的image embeddings(红色部分),同时通过Mask R-CNN(Backbone+RPN+RoIAlign支路)产生类别无关的region embeddings(紫色部分),image embeddings和region embeddings需要进行知识蒸馏。基本类别(绿色部分)转化成文本送入Pre-trained Text Encoder产生text embeddings(绿色部分),将region embeddings和text embeddings进行点积然后softmax归一化,监督信号是对应类别位置1,其余位置为0。
推理阶段
将基本类别和新增类别转化成文本送入Pre-trained Text Encoder产生text embeddings(分别为绿色和蓝色部分),同时通过Mask R-CNN产生类别无关的region embeddings,然后将region embeddings和text embeddings进行点积然后softmax归一化,新增类别(蓝色部分)取最大值的类别为该区域的预测结果。
下面详细讲一下如何选取cropped regions和如何进行knowledge distillation的。
Cropped Regions
将crop和resize的proposals定义为CLIP的图像输入,ViLD同时集成了1x和1.5x(更多的上下文)的cropped regions,并且进行归一化,公式如下:
随后通过NMS保留置信度为topk的regions。该方法速度会非常的慢,因为是一个一个region送入CLIP的,其实就是最原始的R-CNN做法(暗示可以改进的点)。
Knowledge Distillation
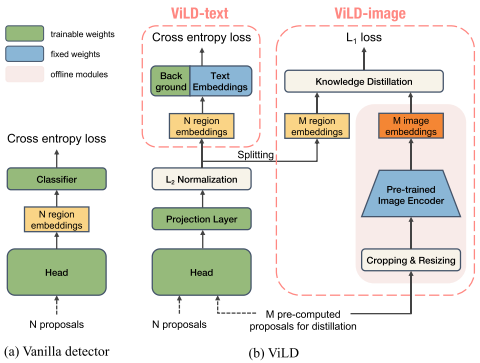
图(a)是Mask R-CNN框架,N proposals送入head得到N region embeddings,然后送入分类器进行分类。图(b)是ViLD的框架,其中Text Embeddings是通过Pre-trained Text Encoder产生的,将M个需要进行蒸馏的proposals同时送入左边分支和右边分支,左边分支的M个proposals经过归一化得到M region embeddings和右边分支产生的M image embeddings进行蒸馏(为了保证ViLD的region embeddings和CLIP的image embeddings映射空间一致),其他由Mask R-CNN产生的N个region embeddings按照IoU给标签,其中没有匹配标签的标记为background,并且给background增加了一个可学习的own embedding()。假设region embedding表示为
,
表示text embeddings,
表示区域r的类别。那么ViLD-text分支的cross entropy loss函数为:
其中。推理阶段因为新增类别,
会变成
。
ViLD-image分支的知识蒸馏函数为:
最终ViLD的训练loss函数为:
实验结果
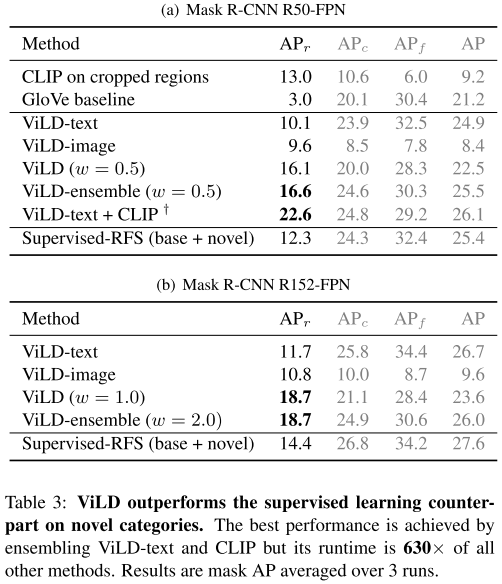
ViLD在新增类别上的精度大幅度超过之前的Supervised方法。

可视化说明了ViLD能够检测新增类别和基本类别的对象,并且新增类别有着高质量的边界框和mask。
我的一点疑问
ViLD最主要的宣扬点是R-CNN对Mask-RCNN进行知识蒸馏,但是据我所知,这种方法DCNv2才是首创,ViLD这么极力宣扬,但是又没有加引用是否不妥?
这里放一张Deformable ConvNets v2: More Deformable, Better Results的知识蒸馏图片,和ViLD的知识蒸馏几乎一模一样。
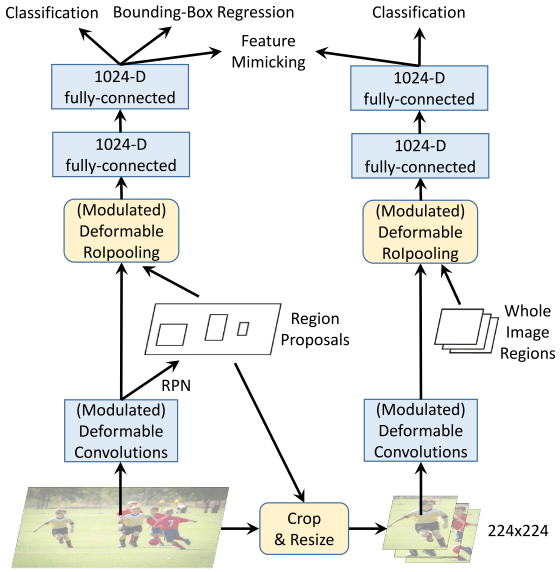
详细信息可以看一下之前知乎上对于DCNv2的讨论
总结
总体上来看,ViLD是一个完成度很高的工作,通过知识蒸馏的设计在新增类别上Zero-Shot超过Supervised的精度,同时也给其他task如何使用CLIP来做Zero-Shot打了个样。有一种强烈的预感,一大波Zero-Shot要扑面而来。
CLIP+Seg
CLIP+SOT
CLIP+MOT
CLIP+X
Reference
[1] Learning Transferable Visual Models From Natural Language Supervision
[2] Zero-Shot Detection via Vision and Language Knowledge Distillation
[3] Deformable ConvNets v2: More Deformable, Better Results
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢