
FM模型作为推荐系统领域的一个独立创新,不仅是浅层学习时代的主流模型,而且对深度学习时代的模型演化也产生了深刻的影响。本章将介绍几个经典的FM家族模型,并从内部演化的角度来探讨它们之间的联系与区别,这几个模型如图1中的虚线框所示。
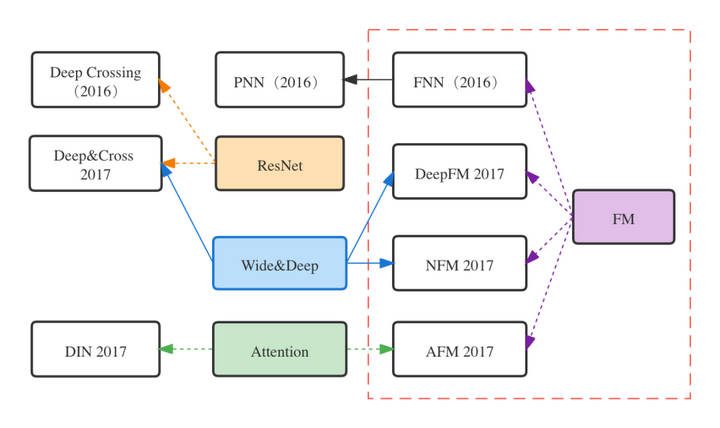
首先,我们先简要回顾一下FM模型(更详细的介绍请见之前的文章:再看FM模型)。FM是因子分解机(Factorization Machines,2010)的简称,实现了特征的两两自动交叉,通过特征隐向量的内积来学习交叉特征的权重。公式表示为:
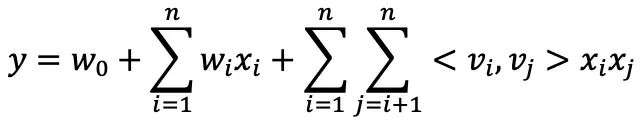
其中vi是特征xi的隐向量,vj是xj的隐向量,<vi,vj>表示内积。
FNN模型
FNN模型是2016提出来的,当时各大公司都还在探索如何将深度学习技术应用于推荐系统,一些头部公司开始了初步的尝试,比如Google应用并发表了Wide&Deep模型,微软在Bing的搜索广告场景尝试了Deep Crossing模型,都是那个时代的代表模型,对业界发展起到了重要作用。不过即使是号称完全自动化特征工程的Deep Crossing模型,也没有做显式特征交叉。那深度学习时代,能否让模型既有像FM那样做显式特征交叉,又具备DNN的隐式高阶交叉和泛化能力呢?FNN就是这样的尝试,试图将FM和DNN结合起来,模型结构如图2所示。
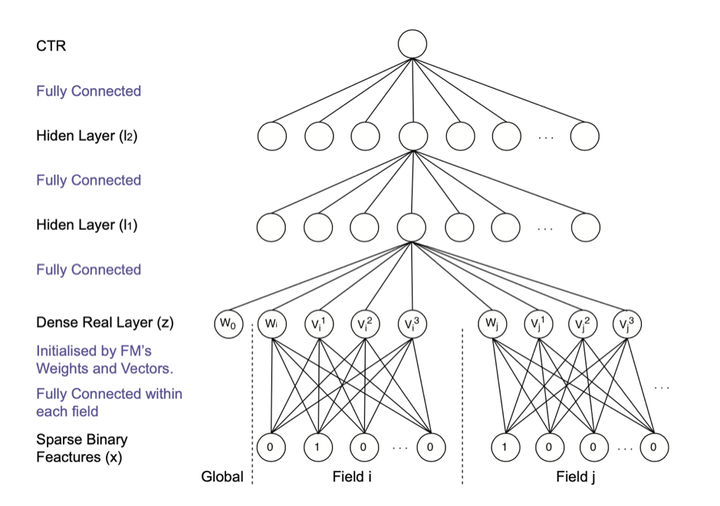
模型的核心思想是采用FM训练得到的隐向量作为神经网络第一层权重的初始值,之后是隐藏层,最后是点击率预估的输出。其实是一个Embedding + MLP结构,特殊的是Embedding的初始值是FM模型已经预训练好的结果。FM与Embedding的初始化对应关系如图3所示。
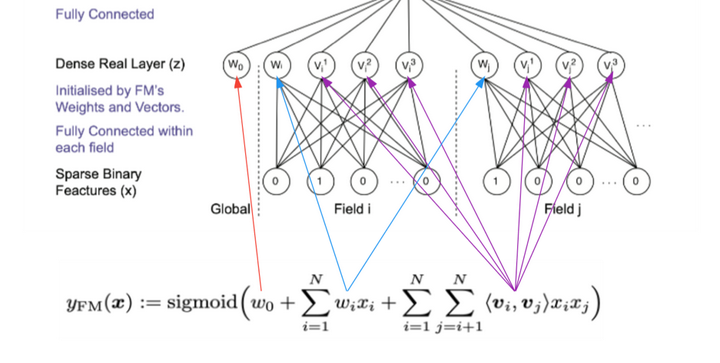
由于Embedding的初始值得到了FM的预训练,因此在训练DNN的时候,模型收敛速度更快;并且Embedding包含了组合特征的信息,可以不用做额外的特征工程;DNN在FM的基础上对特征组合做了进一步的高阶特征组合,模型能得到更好的效果。不过由于整个训练过程分成了两阶段,其实不是一个端到端的训练过程,而是一种基于参数的迁移学习。
FNN存在的问题有:
1. Embedding参数受FM的影响,模型能力受限于FM表征能力的上限;
2. 训练过程分两阶段进行,过程较复杂,效率不高;
3. FNN只能学习高阶特征组合,没有对低阶特征建模,但很多特征的高阶交叉是无意义的。
NFM模型
FNN探索了FM与DNN相结合的方式,而Wide&Deep则给出了一种模型组合的思路,NFM通过设计一种结构,把FM和DNN直接组合了起来,不同于FNN需要两阶段训练,NFM是一个同时包含了FM和DNN两部分的完整模型,训练过程是端到端的。我们先来看一下NFM的公式:
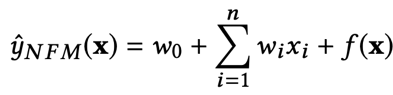
可以看出,与FM的公式相比,前两项是一样的,只有第三项由原来的二阶隐向量内积变成了f(x)。

这是因为作者认为二阶交叉表达能力有限,需要用一个功能更强大的函数来代替,而这个函数就是一个带向量交叉的神经网络。NFM模型如图4所示(这里没有把线性部分画出来)。
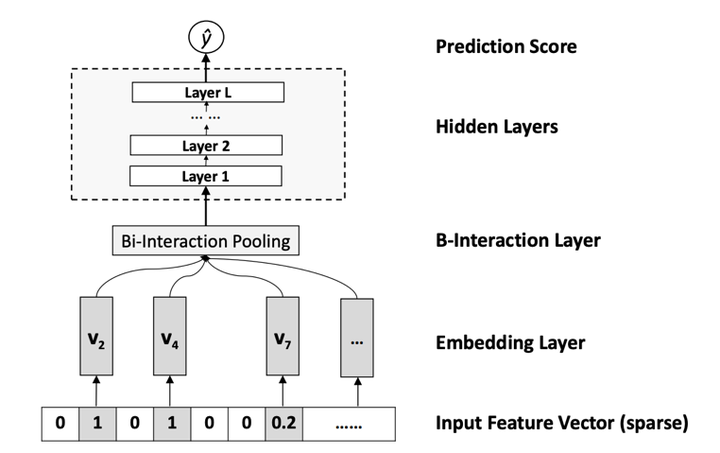
其核心是Bi-Interaction Pooling部分,它的作用是实现输入向量的两两相乘,然后累加起来,再送入DNN做进一步的交叉。
Bi-Interaction Pooling是NFM的核心部分,功能跟PNN中的Product Layer类似,都是实现向量相乘,详细内容可参考之前的文章:PNN。不过在细节处理上,NFM跟PNN以及FM有些不一样。BI层的公式如下:
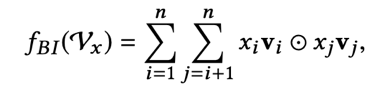
这里是两个向量对应元素的乘积(element-wise product of two vectors),而不是点积,点积之后是一个标量,而BI层的两个向量相乘之后依然是一个k维向量:
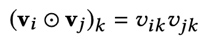
向量两两相乘之后,把所有这些结果向量进行相加(Sum Pooling),得到“一个”k维向量,起到了池化的作用。对于FM模型来说,到这一步就结束了,但NFM还会将这个k维向量送入DNN做进一步的非线性变换,使得FM的能力通过神经网络得到进一步的增强,一些更高阶的特征交叉得到了隐式的实现。
通过BI层,NFM把FM的显式二阶交叉和DNN的隐式高阶交叉能力组合到了一起,训练时,参数可以通过DNN反向传播到FM的隐向量进行统一更新,实现了真正的端到端训练。
在实现上,NFM在BI层采用了Dropout来避免过拟合,采用了BatchNormalization避免输入层的参数分布改变隐藏层和输出层的分布。论文通过实验还发现DNN网络并不是越深越好,1层的网络效果优于更多层,也优于0层。
AFM模型
AFM可以看作是对NFM功能的增强,实际上NFM的作者参与到了AFM的研究当中。AFM模型的最大贡献是将Attention机制引入到了特征交叉模块。在NFM的BI层,对交叉特征的向量进行Sum Pooling时是没有权重的,对所有的特征交叉都一视同仁,平等对待。但实际中,不同的特征组合对结果的影响程度是有差别的,通过Attention机制可以显式地将这些差异学习出来,增加了信息量,可以对模型的效果带来提升,同时还对可解释性带来了帮助。例如在广告推荐场景中,对于特征组合“女性+曾经购买过化妆品”对是否购买“口红”商品的影响要强过特征组合“30岁+宁波”。
AFM的核心是在特征交叉层与输出层之间,增加了Attention网络,结构如图5所示。
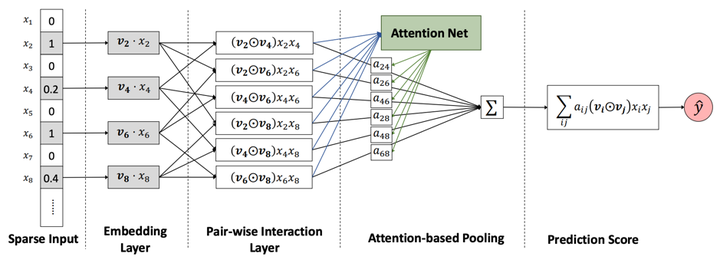
其中Pair-wise Interaction Layer跟NFM中的Bi-Interaction Layer(去除Pooling的话)是一样的。AFM的核心是Attention-based Pooling层,公式如下:
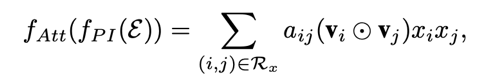
两两向量交叉之后,与一个注意力分数a相乘,表示这组交叉对于最终输出的影响程度,其中a也是通过训练学到的。论文中采用了一个MLP来实现Attention Net,用来学习a。采用MLP的另一个好处是对于从未出现过的特征组合也具备一定的泛化能力。该注意力网络是一个简单的全连接加上softmax作为输出。
AFM最终的输出如下列公式:
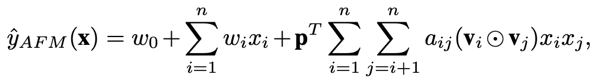
除了带注意力机制的交叉部分外,依然保留了线性部分。还可以看出,相对于NFM,AFM没有后面的DNN部分。不过从各种组合模型相对丰富的今天来看,读者完全可以根据自己的数据特点做模型的扩展和修改。
DeepFM模型
DeepFM是一个经典的模型,从今天的角度来看,它又是一个简单的模型。如果把Wide&Deep看作是LR + DNN的话,那DeepFM基本上就是FM + DNN了。可以把DeepFM看作是Wide&Deep的升级版,它用FM来代替Wide&Deep的Wide侧。当然这不是简单的替换,而是做了很多细节处理,比如对输入做了改进,FM和DNN两部分共享同一Embedding层。模型的整体结构如图6所示。
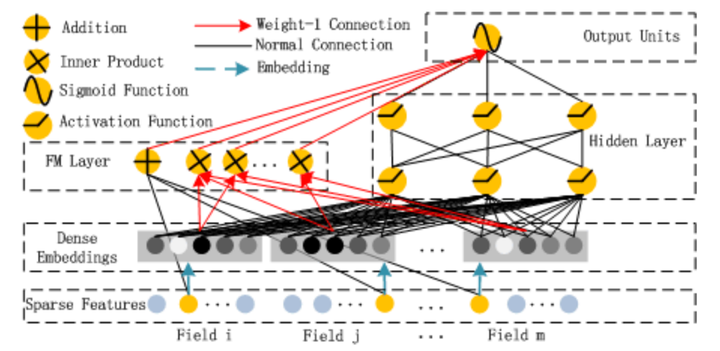
模型的左侧是FM部分,其中又包含了一阶特征和二阶交叉特征;右侧是一个DNN网络,左右两边共享Embedding输入;输出层是两侧输出之和,公式如下:
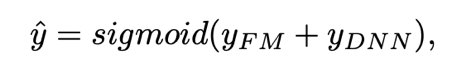
DeepFM模型具备以下特点:
1. 能同时学习低阶显式特征组合和高阶隐式特征组合;
2. FM部分和DNN部分共享Embedding,可以更有效率地学习;
3. 相对于FNN,不需要预训练FM模型;
4. 不需要人工特征工程。
论文中,DeepFM与其他一些模型的效果做了对比,优势还是挺明显的。如下表:
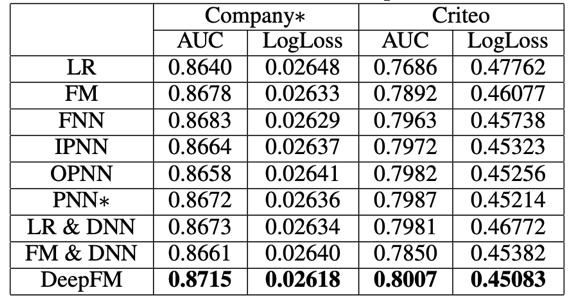
当前很多公司的广告系统或推荐系统都以DeepFM作为深度学习的第一个模型或者一个重要的基准模型。
至此,深度学习中的几个经典的FM家族模型就全部介绍完了(FNN、NFM、AFM、DeepFM)。另外,我把xDeepFM模型归纳为是DCN的改进版本,因为除了名字与DeepFM相似之外,实质内容跟DCN更加接近。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢