
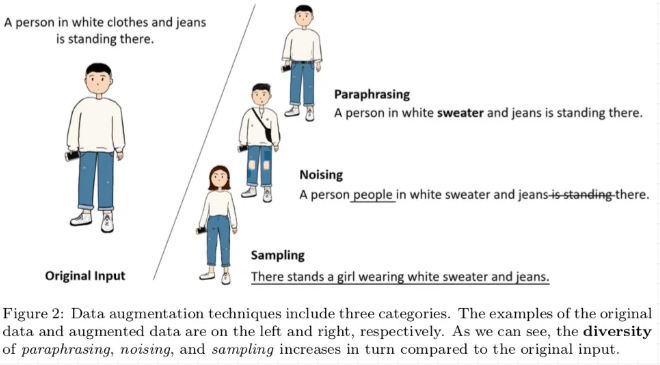
数据增强(Data Augmentation, DA)缓解了深度学习中数据不足的场景,在图像领域首先得到广泛使用,进而延伸到 NLP 领域,并在许多任务上取得效果。一个主要的方向是增加训练数据的多样性,从而提高模型泛化能力。
今天分享一篇全面和结构化的数据增强综述,将 DA 方法基于增强数据的多样性分成三类:释义、噪声和采样,分别进行详细分析,另外也介绍了它们在 NLP 任务中的应用和挑战。

论文链接:https://arxiv.org/pdf/2110.01852.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢