
论文标题: Pose-guided Feature Disentangling for Occluded Person Re-identification Based on Transformer
论文链接:https://arxiv.org/abs/2112.02466
代码链接:https://github.com/WangTaoAs/PFD_Net
作者单位:北京大学
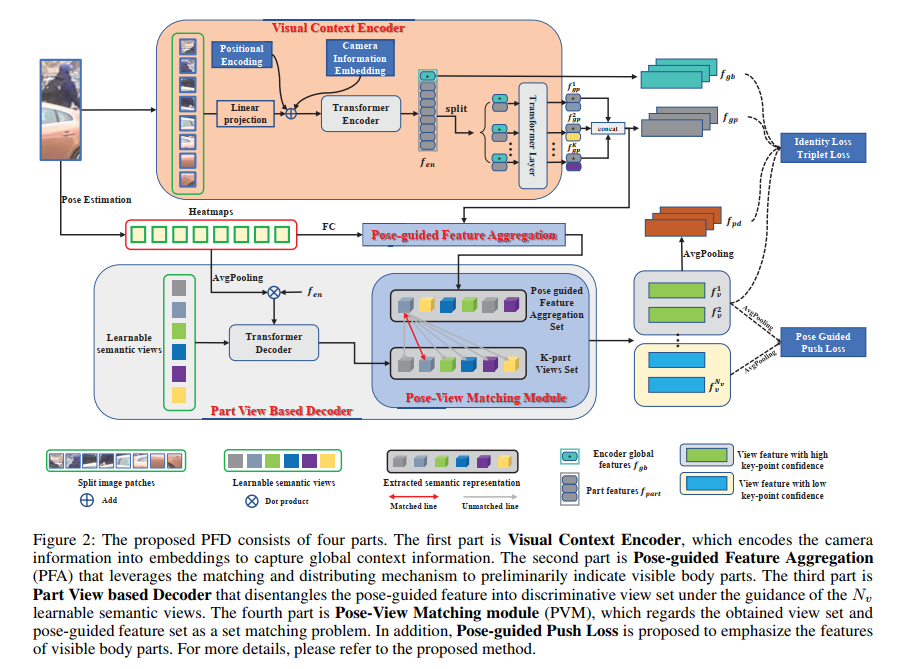
被遮挡的人重新识别是一项具有挑战性的任务,因为在某些场景中,人体部位可能会被某些障碍物(例如树木、汽车和行人)遮挡。一些现有的姿势引导方法通过根据图匹配对齐身体部位来解决这个问题,但这些基于图的方法并不直观和复杂。因此,我们提出了一种基于Transformer的姿态引导特征解缠 (PFD) 方法,利用姿态信息清楚地解开语义成分(例如人体或关节部位),并相应地选择性地匹配未遮挡的部分。首先,Vision Transformer(ViT)以其强大的能力用于提取patch特征。其次,为了初步从补丁信息中分离出姿势信息,在姿势引导特征聚合(PFA)模块中利用了匹配和分配机制。第三,在转换器解码器中引入了一组可学习的语义视图,以隐式增强解开的身体部位特征。但是,在没有额外监督的情况下,不能保证这些语义视图与主体相关。因此,提出了姿势视图匹配(PVM)模块来显式匹配可见的身体部位并自动分离遮挡特征。第四,为了更好地防止遮挡的干扰,我们设计了一个 Pose-guided Push Loss 来强调可见身体部位的特征。对两个任务(遮挡和整体 Re-ID)的五个具有挑战性的数据集的广泛实验表明,我们提出的 PFD 非常有前途,与最先进的方法相比表现出色。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢