
NLP算法工程师,通过句法分析,我们可以得到以下结果:
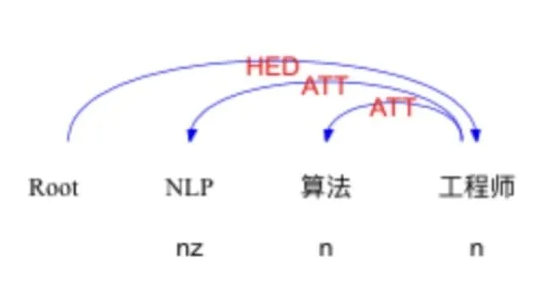
工程师是这个职位的中心词,NLP和算法都是修饰词。
所以,从语言学的角度上来说,NLP算法工程师应该首先成为一个工程师,即工程能力。
而从实际的工作分配来看,绝大多数的人的大部分时间都在做工程,即80%的工程+20%的算法。
无独有偶,最近看到一篇文章,对算法工程师的技能也进行了总结,并形成模型调优能力、数据分析能力、离线任务能力以及在线服务能力,这也验证了业界对算法工程师的职业能力认识。
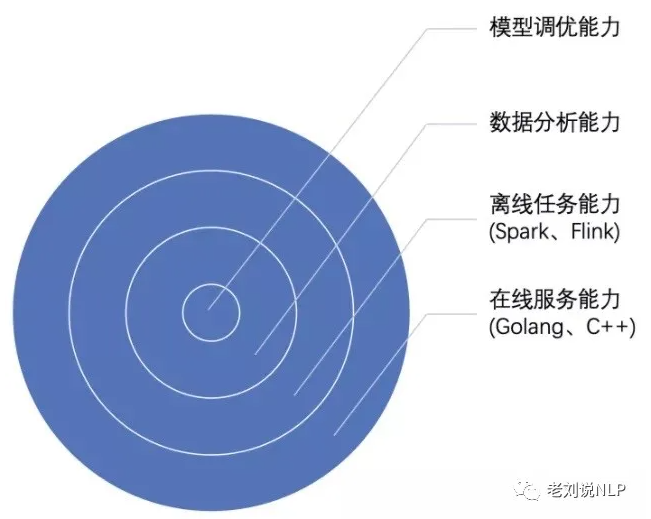
实际上,在老刘看来,一个优秀的自然语言处理工程师,应该是在基础编程工具、业务建模、数据处理、NLP专业知识等多个方面都有一定的掌握程度。
一方面,NLP算法工程师存在的价值是针对一个业务问题或业务场景,能够通过业务模型建模【无论是深度的、策略的,还是牛逼的还是朴素的】,提供一个合格的解决方案,并完成问题的求解。
另一方面,NLP算法工程师大多数都是按照github+Clone+data-modify+Flask+docker的工作模式来完成的,这是我们需要正视的一个现状。只有少数或极少数人员会进行模型设计、研究的工作。这就更说明了,我们需要有足够硬的问题定义能力、解决方案搜索能力(github)以及模型运行能力(clone 以及调参)。
此外,NLP算法工程师,既然是NLP,那么就必须对其处理对象有足够的认识【这一点往往被太多人忽视】,深度学习大行其道的现今,对于文本的一些基本句法、词性、统计语言模型经典方法还是需要了解一些。
因此,为了进一步说明以上观点,本文从python编程基础、爬虫解析基础、数据处理基础、NLP模型基础四个方面进行介绍,总结出50道题。
一、python编程基础
1.如何检测字符串中只含有数字?
2.将字符串"ilovechina"进行反转
3.有一个字符串开头和末尾都有空格,比如“ adabdw ”,要求写一个函数把这个字符串的前后空格都去掉。
4.获取字符串”123456“最后的两个字符。
5.一个编码为 GBK 的字符串S,要将其转成 UTF-8 编码的字符串,应如何操作?
6.单引号、双引号、三引号的区别?
7.a = "你好 中国 ",去除多余空格只留一个空格。
8.已知 AList = [1,2,3,1,2],对 AList 列表元素去重,写出具体过程。
9.如何实现“1,2,3”变成 [“1”,“2”,“3”]
10.给定两个 list,A 和 B,找出相同元素和不同元素
11.[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
12.如何打乱一个列表的元素?
13.请合并下面两个字典 a = {“A”:1,“B”:2},b = {“C”:3,“D”:4}
14.如何把元组(“a”,“b”)和元组(1,2),变为字典{“a”:1,“b”:2}
15.Python 常用的数据结构的类型及其特性?
16.如何将元组(“A”,“B”)和元组(1,2),合并成字典{“A”:1,“B”:2}
17.我们知道对于列表可以使用切片操作进行部分元素的选择,那么如何对生成器类型的对象实现相同的功能呢?
18.a="hello"和 b="你好"编码成bytes类型
19.下面的代码输出结果是什么?
a = (1,2,3,[4,5,6,7],8)
a[2] = 2
20.下面的代码输出的结果是什么?
a = (1,2,3,[4,5,6,7],8)
a[5] = 2
21.在读文件操作的时候会使用 read、readline 或者 readlines,简述它们各自的作用
二、爬虫解析基础
22.scrapy框架有哪几个组件/模块?简单说一下工作流程。
23.scrapy如何实现分布式抓取?
24.爬虫使用多线程好?还是多进程好?为什么?
三、数据处理基础
-
给定以下xml:
要求提取出所有的data数据和code数据
26.简述几种自然语言处理开源工具包
27.简述常用的知识图谱构建的关键步骤
四、自然语言处理基础
28.编写正则表达式,要求提取出中文中的AABB,ABAB,ABAC四字组合。
例如:给定以下文本:这是一个不真不假的故事,你一五一十的跟我说为什么会出现这样的事情,让我们几个人开心开心,这样以来,我们开心了,我们才能热热闹闹地办好这件事,然后让你开开心心的回去。 输出:不真不假、开心开心、热热闹闹、开开心心
29.TFIDF的计算公式及主要思想
30.编写正向最大匹配分词算法
40.假设语料库词总数为13748,并给定以下语料统计数据:
要求:
1)运用bi-gram计算句子‘I want to eat Chinese food’的生成概率
2)如果语料不足,通常会导致很多ngram对在语料库中不存在,这样会造成什么问题,通常要采取什么措施?
41.词向量有哪些获取方法?简述你使用过的词向量训练模型原理,如可以,画出示意图。
42.交叉熵与信息熵,相对熵(KL散度),具体如何计算?
43.交叉验证是什么?为什么使用交叉验证?
44.文本情感分析中,需要依赖外部情感字典,对情感词扩展的方法有哪些?请阐述说明。
45.深度学习中,特征选择方法有哪些?
46.BERT的具体网络结构,以及训练过程,BERT中的Embedding都包括哪几部分Bert 采用哪种Normalization结构,LayerNorm和BatchNorm区别,LayerNorm结构有参数吗,参数的作用?
47.如何优化BERT性能?BERT在工业落地时候,如何保证QPS达标?
48.如何理解Multi-head attention,Bert源码中多头的维度如何变化的,Bert是双向模型,双向体现在哪?Bert的位置编码和transformers的位置编码一样么?
49.如何解决样本不平衡的问题?都见过什么评价指标,precsion,accuray,f1-score,recall,auc的区别与含义。
50.遇到过什么数据标注问题?对于漏标、错标等数据标注问题通常都有哪些解决方案。
五、总结
本文从python编程基础、爬虫解析基础、数据处理基础、NLP模型基础四个方面进行介绍,总结出50道题。
基础不牢,地动山摇。
切记,切记。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢