
这篇文章『Meta-FDMixup: Cross-Domain Few-Shot Learning Guided by Labeled Target Data』是 ACM Multimedia 2021 上的工作,主要是做 cross-domain few-shot learning,文章主要提出使用极少一部分 target 带标注数据来帮助模型的学习。

论文链接:
https://arxiv.org/abs/2107.11978
项目链接:
https://github.com/lovelyqian/Meta-FDMixup
论文解读:
https://www.bilibili.com/video/BV1xT4y1f7B6?spm_id_from=333.999.0.0
本文提出了一种更加现实可操作的场景:不管target data是鸟类,植物,还是医疗,获取极少数量的属于target domain标注数据其实并不是一件难事(现有benchamark本身有可以使用的这部分数据,即使没有,人工标注产生极少一部分这样的标注数据代价也不高)。因此,作者首先提出learning CD-FSL with extremely few labeled target data。为了便于区分,将这部分数据成为auxiliary data。
整体的网络框架图如下所示:
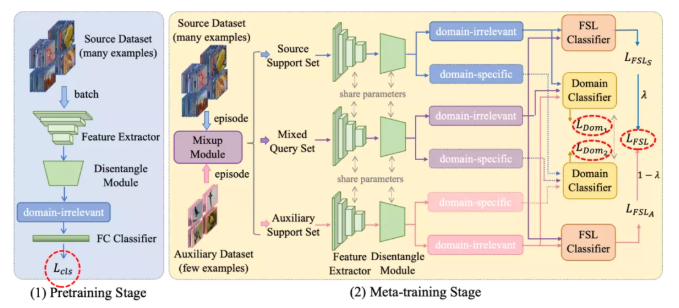
文章主要包括以下五个模块:
-
feature extractor:用于提取整体视觉特征;
-
disentangle module:从整体视觉特征中拆解domain-irrelevant以及domain-specific features;
-
mixup module:对来自source的training data和auxiliary data进行mixup,以便充分使用各个数据;
-
FSL classifier:根据domain-irrelevant features对episode中的query images进行分类,得到分类结果;
-
domain classifier:判断输入特征来自哪个domain,进而用于监督disentangle module的学习;
整体的训练过程分为两个部分:1)pretrain;2)meta-train。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢