
以自然语言文本作为输入,经过CNN、RNN、LSTM、Transformer等特征编码器进行特征提取,然后后接softmax等解码方式完成标签预测,这一过程是当前NLP处理的标准流程。而自从预训练语言模型推出以来,以BERT为代表的预训练语言模型正在引领NLP任务的新范式。
但无论是标注流程还是BERT范式,其实际上建模的只是当前输入文本的信息,如词法信息、句法分析以及字符之间的上下文共现关系。汇总的来说,这些知识信息只是一个序列文本,涵盖的是字符与字符之间的共现、搭配信息,以及字符或词语自身的embedding信息。
例如,从BERT的实现原理上,我们可以看到,BERT 在处理中文语言时,通过预测汉字进行建模,模型很难学出更大语义单元的完整语义表示。例如,对于乒 [mask] 球,清明上 [mask] 图,[mask] 颜六色这些词,BERT 模型通过字的搭配,很容易推测出掩码的字信息,但没有显式地对语义概念单元 (如乒乓球、清明上河图) 以及其对应的语义关系进行建模。
又如,传统的文本生成任务只依靠输入文本进行生成,缺乏更加丰富的“知识”信息,因此生成的文本往往非常乏味,缺少有意思的内容。
因此,如何将单一输入文本的其他类型的知识信息融入到模型当中,成为了现在提升模型性能的一个重要方向,并且已经被证明可以提升模型结果。如下图列举了一些现有知识图谱融合的预训练模型放大、知识相关的损失loss,以及所使用的知识来源。
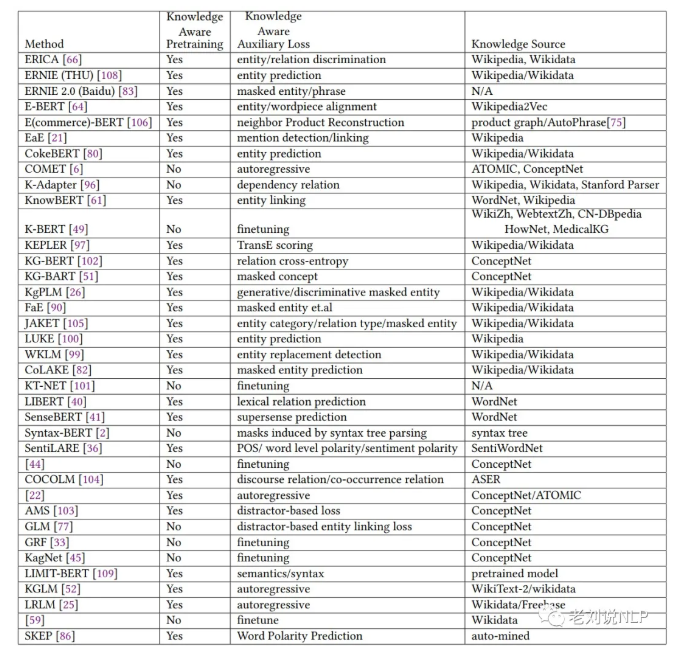
本文主要围绕知识融合自然语言处理模型这一主题展开论述,尝试从这两个方面进行总结,先介绍语言模型可以融合的知识类型,然后分别以当前较为流行的THU-ERNIE以及BAIDU-ERNIE的知识增强方法进行解析。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢