
本文提出了标签幻觉(label hallucination)的简单策略,以便从新类别的小样本中有效地微调大容量模型,在四个小样本分类基准上表现SOTA!性能优于IER-distill等网络,代码已开源!

论文链接:https://arxiv.org/abs/2112.03340
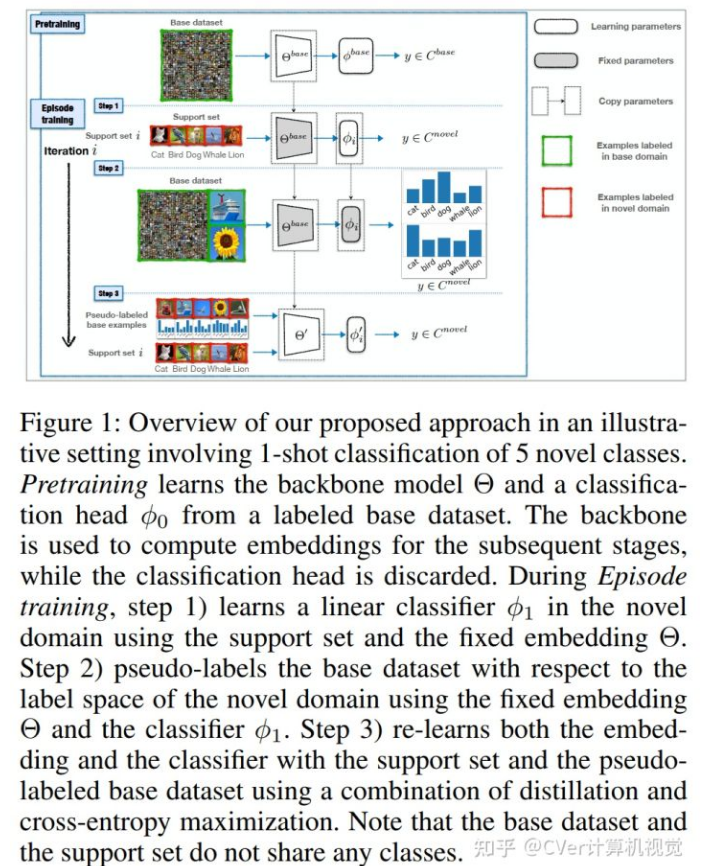
小样本分类需要调整从大型带注释的基础数据集中学到的知识,以识别新的未见类,每个类都由少数标记示例表示。在这种情况下,在大数据集上预训练大容量网络,然后在少数示例上对其进行微调会导致严重的过拟合。同时,在从大型标记数据集学习到的“冻结”特征之上训练一个简单的线性分类器无法使模型适应新类的属性,从而有效地导致欠拟合。
在本文中,我们提出了这两种流行策略的替代方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢