
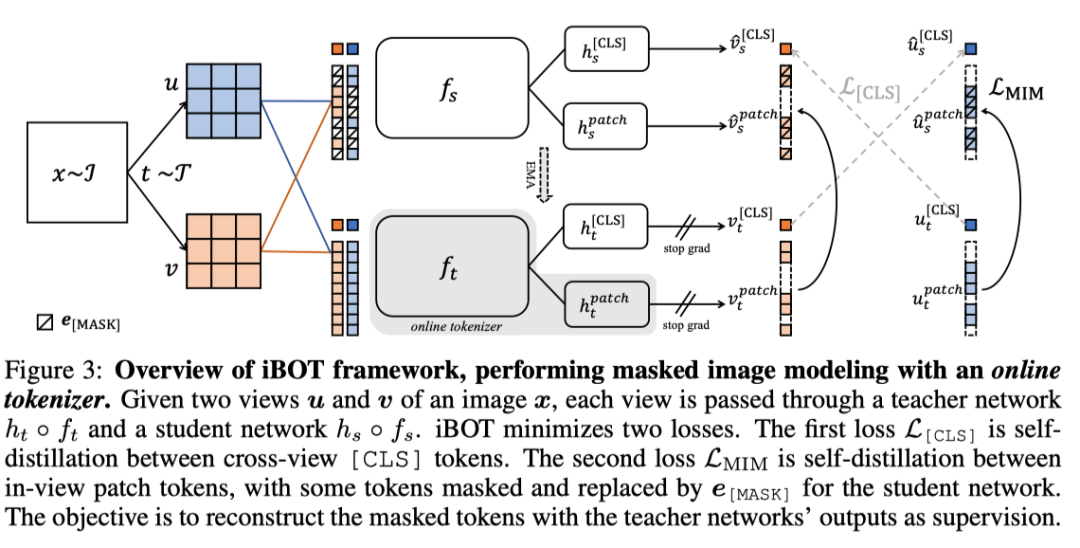
语言Transformer的成功主要归功于masked language modeling(MLM) 的预训练任务,其中文本首先被标记为语义上有意义的片段。在这项工作中,作者研究了masked image modeling(MIM) ,并指出了使用语义上有意义的视觉标记器(visual tokenizer) 的优势和挑战。作者提出了一个自监督的框架iBOT ,它可以通过在线标记器(online tokenizer) 执行mask预测。
具体而言,作者对masked patch tokens进行自蒸馏,并将教师网络作为在线标记器,同时对class token进行自蒸馏以获得视觉语义。在线标记器可与MIM目标共同学习,无需多阶段训练pipeline,其中tokenizer需要事先进行预训练。
作者通过在ImageNet-1K上实现81.6%的linear probing精度和86.3%的微调精度,展示了iBOT的有效性。除了SOTA的图像分类结果外,作者还强调了局部语义模式,这有助于模型获得针对常见损坏的强大鲁棒性,并在密集的下游任务(例如,目标检测、实例分割和语义分割)上取得SOTA的结果。

论文地址:
https://arxiv.org/abs/2111.07832
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢