
中科院自动化所兴军亮研究员领导的博弈学习研究组提出了一种高水平轻量化的两人无限注德州扑克AI程序——AlphaHoldem。其决策速度较DeepStack速度提升超1000倍,与高水平德州扑克选手对抗的结果表明其已经达到了人类专业玩家水平,相关工作被AAAI 2022接收。
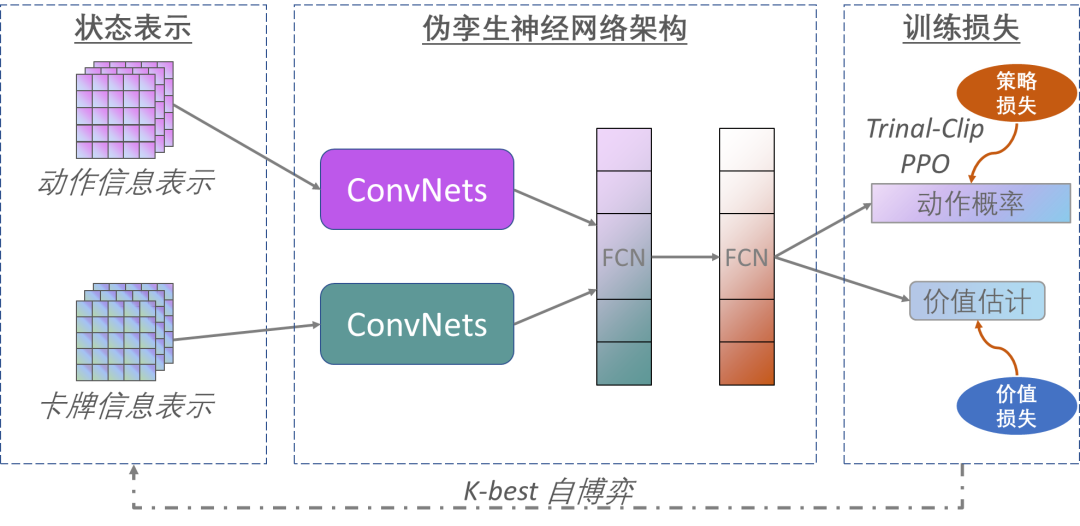
不同于已有的基于CFR算法的德州扑克AI,中国科学院自动化研究所博弈学习研究组基于端到端的深度强化学习算法研发了一款高水平轻量型的德州扑克AI程序AlphaHoldem,其整体架构如下图所示。AlphaHoldem采用Actor-Critic学习框架[8],其输入是卡牌和动作的编码,然后通过伪孪生卷积网络(结构相同参数不共享)提取特征,接下来通过两个全连接层得到状态的高层特征,最终输出动作概率和价值估计。AlphaHoldem的成功得益于其采用了一种高效的状态编码来完整地描述当前及历史状态信息、一种基于Trinal-Clip PPO损失的深度强化学习算法来大幅提高训练过程的稳定性和收敛速度、以及一种新型的Best-K自博弈方式来有效地缓解德扑博弈中存在的策略克制问题。
AlphaHoldem接下来会接入到课题组自研的人机对抗平台OpenHoldem[13](http://holdem.ia.ac.cn/)中供研究者开放测试。OpenHoldem是学术界第一个开放的大规模不完美信息博弈研究平台,包含了多维度评测指标、高性能基准AI以及公开的在线测试环境。
相关论文信息:
Enmin Zhao#, Renye Yan#, Jinqiu Li, Kai Li, Junliang Xing*. High-Performance Artificial Intelligence for Heads-Up No-Limit Poker via End-to-End Reinforcement Learning. In AAAI 2022.
Kai Li, Hang Xu, Enmin Zhao, Zhe Wu, Junliang Xing*. OpenHoldem: An Open Toolkit for Large-Scale Imperfect-Information Game Research. ArXiv preprint arXiv:2012.06168, 2020.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢