
作者:Amanpreet Singh , Ronghang Hu , Vedanuj Goswami等
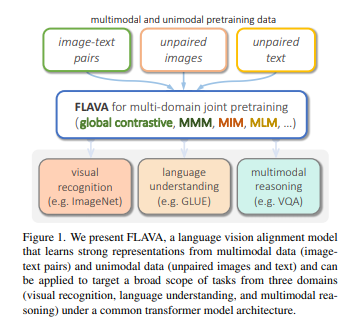
简介:本文主要研究跨模态预训练的基础模型。最先进的视觉和视觉和语言模型依赖于大规模的视觉语言预训练,以便在各种下游任务上获得良好的性能。通常,此类模型通常是跨模态(对比)或多模态(具有早期融合),但不是两者兼有;他们通常只针对特定的模式或任务。一个有研究前景的方向是:使用单一的整体通用模型作为“基础”模型、可以针对所有模态。真正的视觉和语言基础模型应该擅长视觉任务、语言任务以及跨和多模态视觉和语言任务。作者引入 FLAVA 作为这样的跨模态预训练的基础模型,并在跨目标模式的 35 项任务中展示了令人惊叹的性能。
论文下载:https://arxiv.org/pdf/2112.04482
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢