
作者:Tianyi Liu, Zuxuan Wu, Wenhan Xiong等
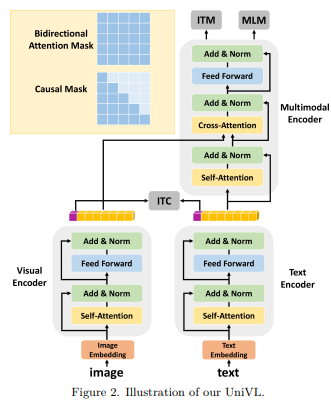
简介:本文研究视频预训练兼顾理解与生成的方法、并提出UniVL框架。大多数现有的视觉语言预训练方法都侧重于理解任务,并在预训练期间使用类似 BERT 的目标(掩码语言建模和图像-文本匹配)。尽管它们在许多理解下游任务中表现良好,例如视觉问答、图像文本检索和视觉蕴涵,但它们不具备生成能力。为了解决这个问题,作者提出了视觉语言理解和生成的统一多模态预训练模型UniVL--- 能够同时处理理解任务和生成任务。作者增加了现有的预训练范式,这些范式只使用带有因果掩码的随机掩码,即掩蔽未来标记的三角形掩码,这样预训练的模型可以通过设计具有自回归生成能力。作者将之前的多个理解任务制定为文本生成任务,并建议使用基于提示的方法对不同的下游任务进行微调。作者的实验表明,在使用相同模型的情况下,理解任务和生成任务之间存在权衡,而改进这两个任务的可行方法是使用更多数据。作者的 UniVL 框架在理解任务和生成任务方面都获得了与最近的视觉语言预训练方法相当的性能。此外,作者证明了基于提示的微调:更具数据效率——在小样本场景中优于区分性/判别方法。
论文下载:https://arxiv.org/pdf/2112.05587
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢