
能否用一个小模型超越GPT3和2800亿参数的Gopher?
Deepmind 的这篇研究论文Improving language models by retrieving from trillions of tokens(通过从数万亿个标记中检索来改进语言模型),表明存在这这样的可能性。
作者:Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, 等
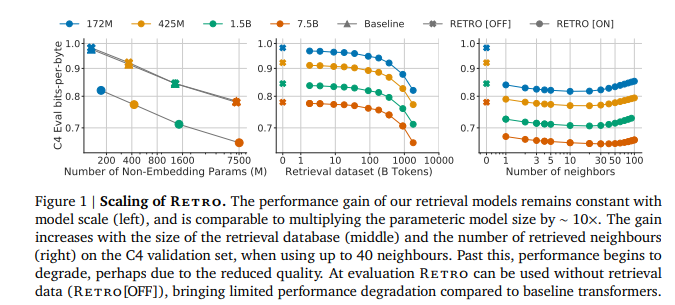
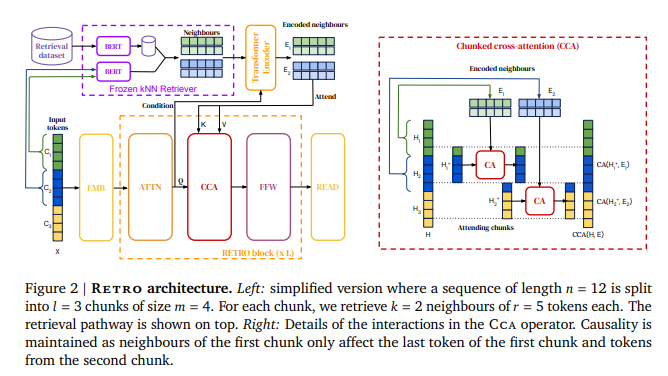
简介:本文基于海量token检索的基础上研究如何改进预训练语言模型。基于与预先标记的局部相似性,作者通过调节从大型语料库中检索到的文档块来增强自回归语言模型。用一个2 万亿令牌数据库,作者提出的检索增强transformer 模型RETRO ,尽管使用了 25%更少的参数、但在 Pile数据集上获得了与 GPT-3 和 Jurassic-1 相当的性能。经过微调,RETRO 性能转化为下游知识密集型任务(例如:问答任务)。RETRO 结合了一个冻结的 Bert 检索器、一个可微分编码器和一个分块交叉注意机制,以根据比训练期间通常消耗的数据多一个数量级的数据来预测令牌Token。本研究建议从头开始训练 RETRO,但也可以通过检索快速 RETROfit 预训练的 Transformer,并且仍然获得良好的性能。本工作为通过空前规模的显性记忆改进语言模型开辟了新途径。
论文下载:https://arxiv.org/pdf/2112.04426
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢