
【论文标题】Extending the WILDS Benchmark for Unsupervised Adaptation
【作者团队】Shiori Sagawa, Pang Wei Koh, Tony Lee, Irena Gao, Sang Michael Xie, Kendrick Shen, Ananya Kumar, Weihua Hu, Michihiro Yasunaga, Henrik Marklund, Sara Beery, Etienne David, Ian Stavness, Wei Guo, Jure Leskovec, Kate Saenko, Tatsunori Hashimoto, Sergey Levine, Chelsea Finn, Percy Liang
【发表时间】2021/12/09
【机 构】斯坦福、加州理工等
【论文链接】https://arxiv.org/abs/2112.05090v1
【资源链接】https://wilds.stanford.edu
预训练模型系统往往是在一个源分布上训练的,但部署在一个不同的目标分布上。无标签数据可以缓解这些分布变化,因为它经常比有标签的数据更可用。然而,现有的无标签数据的分布转移基准并不反映现实世界应用中出现的广泛情况。在这项工作中,本文提出了WILDS 2.0,它扩展了WILDS分布偏移基准中10个数据集中的8个,以包括在部署中实际可获得的精心策划的无标签数据。为了保持一致性,标记的训练、验证和测试集以及评估指标与原来的WILDS基准完全相同。这些数据集涵盖了广泛的应用(从组织学到野生动物保护)、任务(分类、回归和检测)和模态(照片、卫星图像、显微镜切片、文本、分子图)。本文对利用无标签数据的SOTA方法进行了系统的基准测试,包括领域变量、自训练和自监督的方法,并表明它们在WILDS 2.0上的成功。
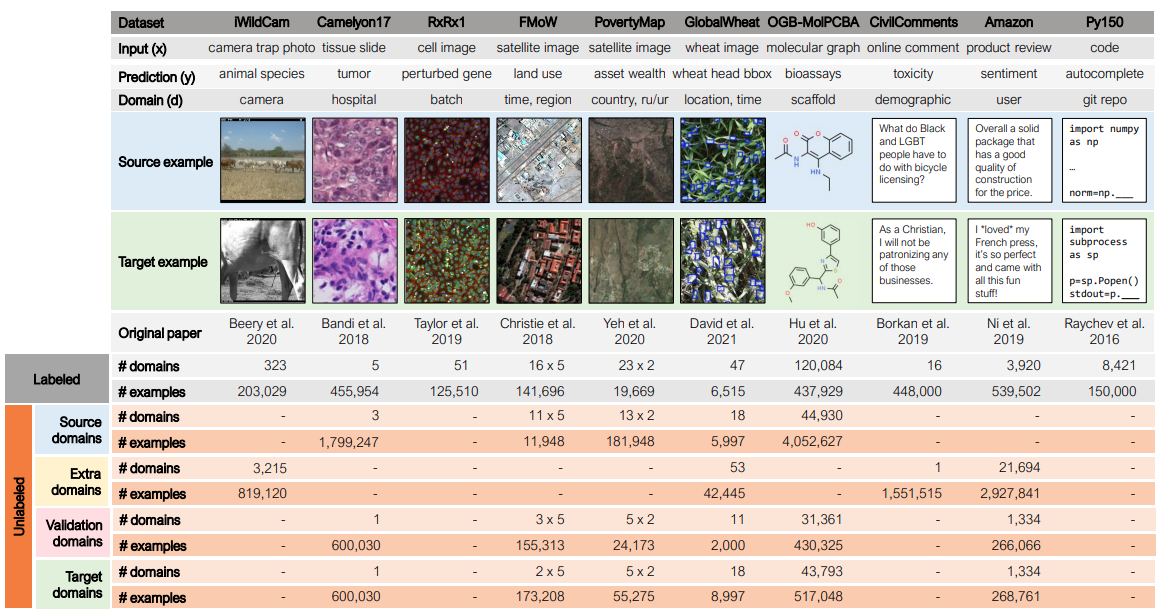
上图展示了WILDS2.0的整体框架,更新了8个Wilds数据集增加了未标记的数据。对于每个数据集,本文保留了Wilds中的标记数据,并将数据集扩大了3-13倍,使用来自同一基础数据集的无标记数据。无标签数据的类型(即它是否来自源域、额外域、验证域或目标域)取决于对应用来说什么是现实的和可用的。除了这8个数据集外,Wilds还包含2个没有无标签数据的数据集:Py150-wilds代码完成数据集和RxRx1-wilds遗传扰动数据集。对于所有的数据集,标记的数据和评估指标与Wilds 1.0中的完全相同。
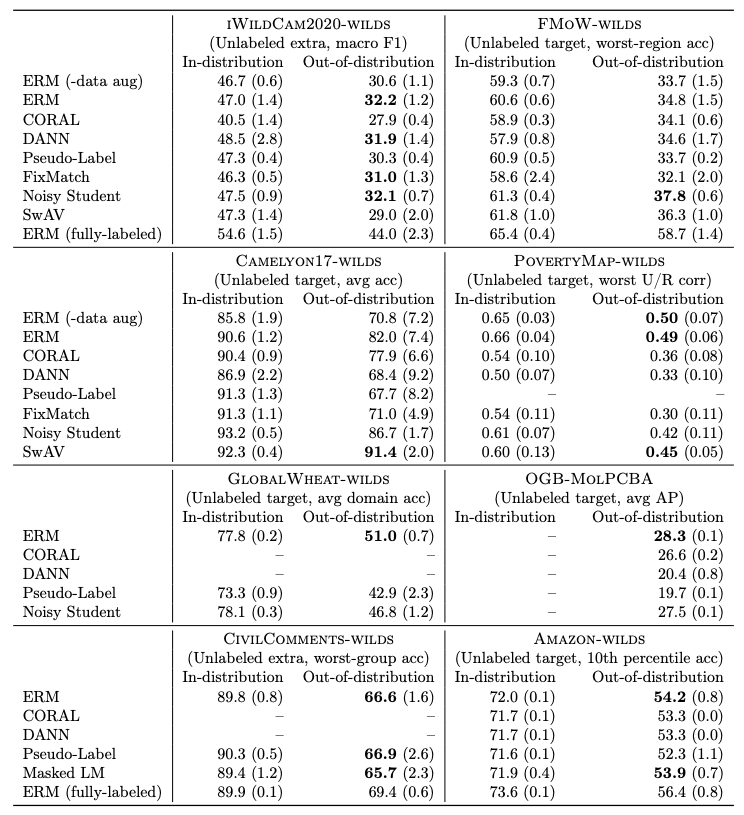
上图展示了每个方法在每个适用数据集上的分布内(ID)和分布外(OOD)性能。本文对每个单元进行了3-10次的重复实验(随机种子),这取决于数据集的情况并报告了各次复制的标准偏差。完全标记的实验在 "未标记的 "数据上使用地面真实标签。本文将最高的非完全标记的OOD性能数字以及标准误差在范围内的其他数字加粗。在每个数据集的名称下面,本文报告了无标签数据的类型和使用的指标。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢