
类别型特征(用户ID/物品ID)的embedding在推荐系统中扮演着重要的作用,标准的方式是用一个(巨大的)embedding table为每个类别特征分配一个embedding。然而这种方式在推荐系统中存在以下几个挑战:
-
参数量巨大(Huge vocabulary size):推荐系统通常包含几百万的用户ID/视频ID,如果每个特征都指定一个embedding会占据大量空间。
-
特征是动态的(Dynamic nature of input):推荐系统中经常会出现全新的用户ID/视频ID,固定的embedding table不能解决OOV(out-of-vocabulary)问题.
-
特征分布高度倾斜(Highly-skewed data distribution):推荐数据中低频特征的训练实例数量较少,因此该特征的embedding在训练阶段就很少更新,对训练的质量有显著影响。
这篇文章提出一个「Deep Hash Embeddings (DHE)」 的方式来缓解以上问题。
论文标题:
Learning to Embed Categorical Features without Embedding Tables for Recommendation
论文链接:
https://arxiv.org/abs/2010.10784v2
DHE将整个特征嵌入分为「编码阶段(encoding)「和」解码阶段(decoding)」。下图是One-hot Embedding与DHE的整体区别:
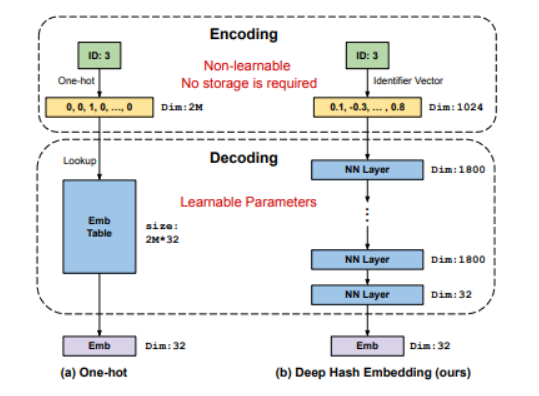
可以看到:
-
One-hot Embedding的编码阶段将特征表示为one-hot的稀疏向量,解码阶段通过巨大的embedding look-up table(可看作一层神经网络)得到该特征的唯一表示。 -
DHE编码阶段通过多个(k=1024个)哈希函数将特征表示为稠密的Identifier vector, 解码阶段通过多层神经网络得到该特征的唯一表示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢