
【作者团队】Jiayou Zhang, Zhirui Wang, Shizhuo Zhang, Megh Manoj Bhalerao, Yucong Liu, Dawei Zhu, Sheng Wang
【发表时间】2021/12/01
【机 构】清华、北大、南洋理工、芝加哥大学、华盛顿大学
生物医学实体规范化统一了整个生物医学实验和研究的语言,并进一步使本文能够获得生命科学的整体观点。目前的方法主要研究比较标准化的实体,如疾病和药物的规范化,而忽略了比较模糊但关键的实体,如通路、功能和细胞类型,阻碍了它们在现实世界的应用。为了在这些未被充分开发的实体上实现生物医学实体的规范化,本文首先引入了一个由专家策划的数据集OBO-syn,其中包括70种不同类型的实体和200万个策划的实体-同义词对。为了利用这个数据集的独特的图结构,本文提出了GraphPrompt,一种基于提示的学习方法,根据图创建提示模板。Graph-Prompt在零样本和小样本设置上分别获得了41.0%和29.9%的改进,表明这些基于图的提示模板的有效性。本文设想,本文的方法GraphPrompt和OBO-syn数据集可以广泛地应用于基于图的NLP任务,并作为分析多样化和积累的生物医学数据的基础。
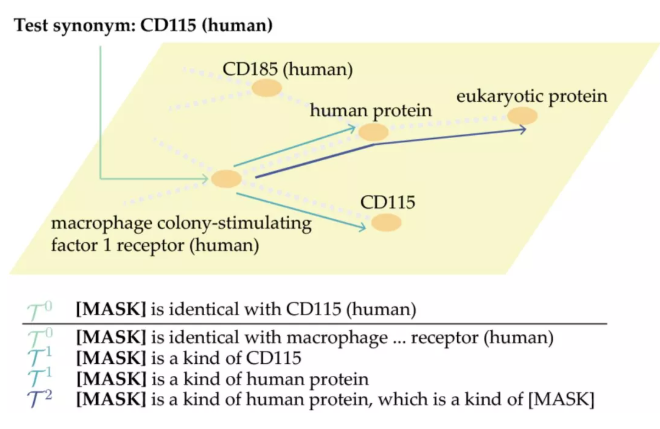
上图为GraphPrompt的实例。GraphPrompt将测试同义词(CD115(human))分类到图中的实体,方法是根据零阶邻居嵌入式图像、一阶邻居嵌入式图像和二阶邻居嵌入式图像,将图转换为提示模板。
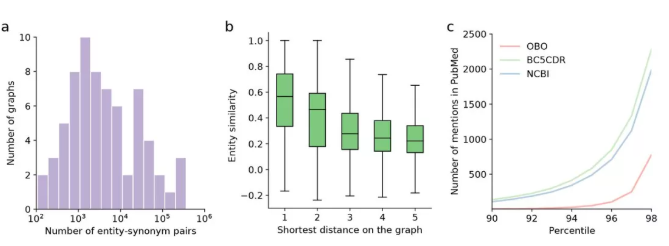
上图显示了对OBO-syn数据集的分析。a图, 显示70个实体-同义词对的数量分布。
b图, 具有不同最短距离的实体对的文本相似性。
c图, 比较NCBI、BC5CDR、OBO-syn的短语提及量。y轴是2800万份PubMed摘要中提及的数量。X轴是按提及次数排序的短语百分数。
motivation:提出了Prefix-Tuning,一种轻量级fintune替代方法,用于对自然语言生成任务进行微调,在使语言模型参数冻结的同时,去优化一个参数量少的 continuous task-specific vector(称为prefix),用词表中的词初始化较好,并且和类别相关。在大多数任务上比finetune好。
method:Prefix-tuning是做生成任务,它根据不同的模型结构定义了不同的Prompt拼接方式,在GPT类的自回归模型上采用[PREFIX, x, y],在T5类的encoder-decoder模型上采用[PREFIX, x, PREFIX', y] 1.把预训练大模型freeze住,因为大模型参数量大,精调起来效率低,毕竟prompt的出现就是要解决大模型少样本的适配 2.直接优化Prompt参数不太稳定,加了个更大的MLP,训练完只保存MLP变换后的参数就行了 3.实验证实只加到embedding上的效果不太好,因此作者在每层都加了prompt的参数,改动较大
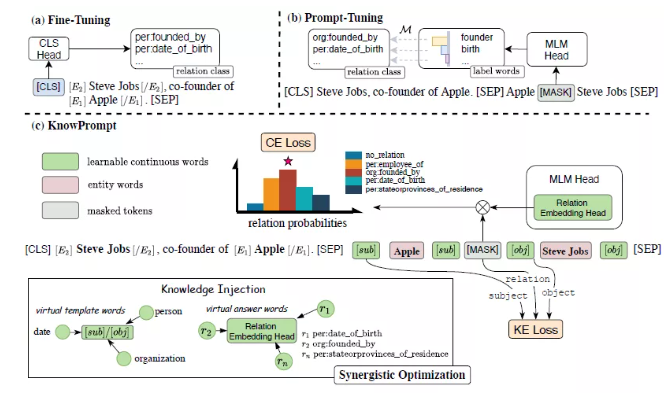
motivation:融入外部知识(实体,关系)的embedding当做参数,将关系分类设置成模板,采用MASK的方式训练,同时增KE的loss
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢