
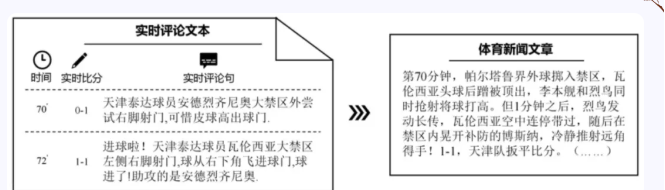
体育赛事摘要是一类特殊的文本摘要任务,旨在根据一场体育比赛的在线评论文本生成对应的新闻报道。如下图所示,其中在线评论文本记录了整场比赛中解说员对当前赛事的实时讲解,由众多评论句组成。除此之外,在线评论文本还包含了每句评论句与其对应的描述时间以及实时比分信息。新闻报道通常是在赛事结束后,由媒体编辑们总结整场比赛发生的核心事件并发布在网络上,便于人们快速地回顾比赛。
体育赛事摘要现有数据集
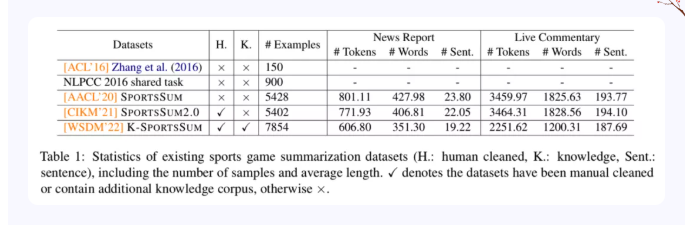
我们整理了现有的5个体育赛事摘要数据集,如下表所示:
现存数据集主要从新浪体育在线(http://match.sports.sina.com.cn/index.html)上收集得到。该网站记录了众多体育赛事的新闻报道与在线评论。又因为足球赛事场次较多且便于收集,现有数据集均面向足球赛事场景。
其中,Zhang等人[1]首次提出了体育赛事摘要任务,并构建了第一个体育赛事摘要数据集,该数据集包含了150场在线评论文本-新闻对。这项工作也启发了众多研究者对该任务的思考。自然语言处理与中文计算会议(NLPCC2016)随后发布了体育赛事摘要评测[2],使用到了包含900个样本的新数据集。这两个早期数据集因为自身规模原因,限制了研究者对于体育赛事摘要任务的探索。
随后SportsSum数据集在AACL2020上被提出[3],这是第一个大规模体育赛事摘要数据集,包含了5428个样本。SportsSum爬取了新浪体育赛事在线中从2012年至2018年的足球赛事,并进行了基于规则的数据清洗。然而经过我们的观察,仅依靠基于规则的清洗方式,数据集仍包含一些噪音,因此我们在SportsSum的基础上进行了人工清洗得到了SportsSum2.0数据集[4],该数据包含了5402个高质量的样本(26个badcase被我们丢弃)。我们的SportsSum2.0作为短文被CIKM2021接受(接受率~28.3%,177/626)。
在研究过程中我们还发现,体育新闻中可能会包含在线评论没有提及到的信息,例如球员的身高、生日,球队过往的荣耀。为此,我们又构建了K-SportsSum数据集[5],不同于以往的数据集,K-SportsSum还包含了一个大型的知识库,该知识库有523个球队以及1万4千多名球员的信息。我们希望这个知识库能够用来缓解在线评论与体育新闻中存在的信息差异。此外,K-SportsSum又收集了从2019年至2020年的足球赛事,在规模上也有一定的扩充。目前这项工作被WSDM2022录用为长文(录用率~20.2%,159/786)。
体育赛事摘要的挑战
长文本理解:由表1中的统计数据可以看出在线评论文本属于长文本,平均包含两千至三千字。远超主流生成式预训练模型(例如BART,T5,PEGASUS)的编码长度限制。再者,核心事件会分散在整个在线评论文本中,信息的分布是不均匀的,因此如何有效地理解在线评论文本是一个棘手的难题。
文本风格差异:在线评论文本与新闻报道之间的文本风格有着巨大的差异。在线评论文本是解说员对比赛的实时讲解,有着口语化的特点,而新闻报道则用正式的用词撰写并发表。这也加大了从在线评论条件生成新闻报道的难度。
事实性问题 [3]:在线评论文本中会大量出现人名,因此在摘要过程中会产生严重的事实性偏差问题。
信息差异 [5]:新闻报道中会时常出现一些在线评论中没有提及过的信息,因此在生成摘要的过程中存在信息差异。
结构差异:不同于其余文本摘要任务,体育赛事摘要的输入,即在线评论文本是半结构化数据,以表格的形式呈现。在生成新闻报道的工程中,需要考虑到其中的半结构化信息。
领域知识:在线评论文本与新闻报道中专业术语使用频繁,用于描述运动员的行为以及处于场地的位置。
体育赛事摘要的方法
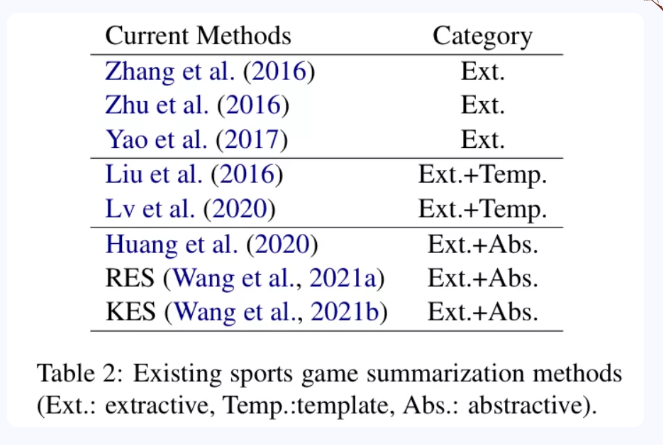
现有体育赛事摘要模型如表2所示,可以看出该任务仍处于探索阶段。我们将现有方法分为三类:
抽取式体育赛事摘要:由于早期数据集的规模有限,研究者们主要探索抽取式的摘要模型,即从在线评论文本中选取重要的评论句以形成新闻。文献[1], [6-7]使用了不同的句子评分方式,考虑评论句包含的信息量,冗余度等信息,为每个评论句进行打分,并选取分值高的评论句组成最终体育新闻。
抽取式+模版:由于在线评论与体育新闻之间存在着巨大的文本风格差异,尽管早期数据集规模有限无法探索生成式摘要模型。文献[8-9]在抽取式的基础上,又利用了人工设定的模版将重要在线评论句改写成最终的赛事新闻。这种方式虽然能够有效缓解风格差异问题,但构建模版需要消耗大量的人力并且灵活性较差。
抽取式+生成式:随着大规模数据集的提出,研究者们开始在体育赛事摘要任务上探索生成式模型。正如我们在上文体育赛事摘要任务挑战性中提到的那样,由于在线评论属于长文本,不好直接进行端到端的生成。因此,研究者们普遍采用pipeline的方式。文献[3]提出了两步模型:先抽取重要的评论句,再将评论句通过seq2seq模型改写成新闻句。文献[4]在此基础上,又通过改进后的MMR算法对生成出的新闻句子进行二次筛选进而组成最终体育新闻。文献[5]则观察到了体育新闻与在线文本之间存在的信息差异问题,通过引入一个包含队伍和运动员信息的大规模知识库来进行缓解。具体地,在从评论句改写成新闻句的过程中,对评论句进行实体识别并实体链接至知识库中的实体(队伍或运动员),并在编码过程中融入相关片段的编码表示。
体育赛事摘要的未来方向
场景更加丰富的数据集:现有的数据集均面向足球赛事,然而体育赛事还包含篮球、网球等热门场景。我们发现新浪体育在线中还存在关于篮球赛事的在线评论。构建一个包含众多赛事场景的数据集能够更好地推进领域的发展,并增强模型的通用性与泛化性。
跨语言与多语言体育赛事摘要:当前关于体育赛事摘要的研究均在中文场景下进行,这是因为国内很多赛事无法转播(版权原因),便催生了在线评论服务,以此来让体育爱好者们近距离感受赛事。构建一个其他语言(例如英语)的体育赛事摘要数据集,并在其中探索跨语言或多语言赛事摘要也将会是有意义的尝试。我们还在文献[10]中发现已经有英文网站提供足球赛事的在线评论服务了,因此在数据获取方面有一定的可行性。
事实性问题:正如我们在挑战性中提到的,由于在线评论文本中频繁出现各类实体名(例如人名,球队名),会导致生成出的新闻报道出现事实性错误的问题。例如在线评论文本中没有出现过的人名却出现在了生成的新闻报道中。文献[3]针对这一问题将所有人名替换为特殊的token,并在生成出新闻中重新替换为原有人名来缓解这一问题。
端到端的探索:由于在线文本的长文本特性,现有生成模型均基于pipeline的方式,随着预训练语言模型的发展,已经诞生了能够处理长文的生成式语言模型,例如longformer-encoder-decoder (LED), 、bigbird。利用长文本预训练模型探索端到端的生成方式能够减少pipeline中存在的错误传播问题。
个性化体育赛事摘要:每个人想通过体育新闻了解到的内容是不一样的,例如一场比赛有球员A和球员B两名主力。球员A的粉丝希望通过新闻报道了解到A的表现,而B的粉丝更希望看到B的出色发挥。因此,为特定的用户生成更加个性化的赛事新闻能够提升体育赛事摘要的实用性。
参考文献:
[1]Zhang, Jianmin et al. “Towards Constructing Sports News from LiveText Commentary.” ACL (2016).
[2]Wan, Xiaojun et al. “Overview of the NLPCC-ICCPOL 2016 Shared Task:Sports News Generation from Live Webcast Scripts.” NLPCC/ICCPOL(2016).
[3]Huang, Kuan-Hao et al. “Generating Sports News from LiveCommentary: A Chinese Dataset for Sports Game Summarization.” AACL(2020).
[4]Wang, Jiaan et al. “SportsSum2.0: Generating High-Quality SportsNews from Live Text Commentary.” CIKM (2021).
[5]Wang, Jiaan et al. “Knowledge Enhanced Sports Game Summarization.”WSDM (2022).
[6]Zhu, Liya et al. “Research on Summary Sentences Extraction Orientedto Live Sports Text.” NLPCC/ICCPOL (2016).
[7]Yao, Jin-ge et al. “Content Selection for Real-time Sports NewsConstruction from Commentary Texts.” INLG (2017).
[8]Liu, Maofu et al. “Sports News Generation from Live Webcast ScriptsBased on Rules and Templates.” NLPCC/ICCPOL (2016).
[9]Lv, Xueqiang et al. “Generate Football News from Live WebcastScripts Based on Character-CNN with Five Strokes.” (2020).
[10]Zhang, Ruochen and Carsten Eickhoff. “SOCCER: An Information-SparseDiscourse State Tracking Collection in the Sports Commentary Domain.”NAACL (2021).
为了方便大家获取上述论文,我们在github上总结了paperlist并进行了分类,请访问:https://github.com/krystalan/K-SportsSum#existing-works
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢