
今天来讲一下NLP最近比较火的prompt,包括简介、各种花式操作及代码实现。之前了解prompt时在网上看了一堆资料,还是感觉懵懵的,所以想要写一篇通俗易懂的prompt介绍,快上车啦~~~
1. prompt的含义
2. 如何设计prompt
3. prompt进阶——自动学习prompt
4. 关键要点
5. 代码实现
1. prompt的含义
prompt顾名思义就是“提示”的意思,应该有人玩过你画我猜这个游戏吧,对方根据一个词语画一幅画,我们来猜他画的是什么,因为有太多灵魂画手了,画风清奇,或者你们没有心有灵犀,根本就不好猜啊!这时候屏幕上会出现一些提示词比如3个字,水果,那岂不是好猜一点了嘛,毕竟3个字的水果也不多呀。看到了吧,这就是prompt的魅力,让我们心有灵犀一点通!(我不太会画哈,大家想象一下就行啦,嘿嘿嘿~~~)
2. 如何设计prompt
在人机交互中,我们想让计算机完成一项任务,是不是也可以给他一点提示呢?可以给什么样的提示呢?是不是可以像“你画我猜”那样给出一些语言型的提示呢?
答案是yes! 本身NLP就是自然语言处理嘛,我们对输入进行改造,在输入之外再接prompt语言,同样还是做NLP,万变不离其宗,本身性质都是一样的,其宗旨就是万物皆可语言模型。
那如何设计prompt呢?本质上可以从以下两类来考虑:
1. 答案提示型prompt, 根据任务的目标、答案的类型设计prompt,通过prompt引出答案。
2. 任务提示型prompt,提醒模型是要做什么任务,因为同样输入一句话,可以做的任务太多了,通过prompt让模型知道这次是要做什么任务。
2.1 答案指示型prompt
拿大家常举的电影评论情感分类任务为例
输入:I like this movie.
输出:这句话的情感极性标签:positive/negative
想象一下你是机器,用户发给你一句话:"I like this movie. " 你怎么知道用户想让你干啥?这时候我们就可以再输入一些答案指示型的语言引导模型做出决策,比如:
输入+prompt:I like this movie. The movie is [mask].
当然,prompt也可以是其他的句子:“The film is [mask]”, "It is a [mask] movie"
[mask]位置就是我们想让模型预测出来的词语。我们知道NLP预训练模型对这种填空题是很擅长的,模型很可能会预测出“good”, "interesting"等词汇,因为它在预训练的时候见过很多类似的说法了。诚然,这并不是我们最终想要的positive/negative类别,不要慌,这时候就需要把预测出来的词汇映射到标签类别中,比如“good”, "interesting"归为positive,至于答案-标签的映射如何设计,这里就不细讲了。
所以prompt并没有想象的那么方便呢,但是它为什么香呢?你发现没,这样一顿操作之后,我们没有增加任何参数,完全可以做无监督任务,直接调用合适的预训练模型,加载预训练的参数,让模型直接预测出结果,虽然增加了prompt模板设计、标签映射等人工操作成本,但它不需要任何数据标注,是不是很香?
当然xxx位置还可以是短语、句子,至于特定的任务该如何设计模板,可以参考CMU
大神写的prompt综述 https://arxiv.org/pdf/2107.13586.pdf。
2.2 任务提示型prompt
用prompt来提示要做什么任务,同一个输入可以有不同的任务:
输入:“I like China. ”
翻译任务: 输入+prompt: "Translate the sentence into Franch: I like China."
回复任务:输入+prompt: "Translate the sentence into system response: I like China."
然后选择文本生成预训练模型得到输出。
3. prompt进阶——自动学习prompt
其实,手工设计prompt还有一个问题是,模型对prompt很敏感,不同的模板得到的效果差别很大。

所以研究学者就提出自动学习prompt向量的方法。因为我们输入进去的是人类能看懂的自然语言,那在机器眼里是啥,啥也不是, 也不能这么说吧,prompt经过网络后还是得到一个个向量嘛,既然是向量,当然可以用模型来学习了,甚至你输入一些特殊符号都行,模型似乎无所不能,什么都能学,只要你敢想,至于学得怎么样,学到了什么,还需进一步探究。
笔者在这里简要介绍几个相关模型,更多的模型、更多的坑还需大家来填补了。
3.1 P-tuning——token+vector组合成prompt
为了方便,我们称上面自然语言形式的prompt为基于token的prompt。我们讲到要将token换成向量(vector),但是又不能一口吃个大胖子,全部给换成vector,所以就出现了token+vector组合形式的prompt。
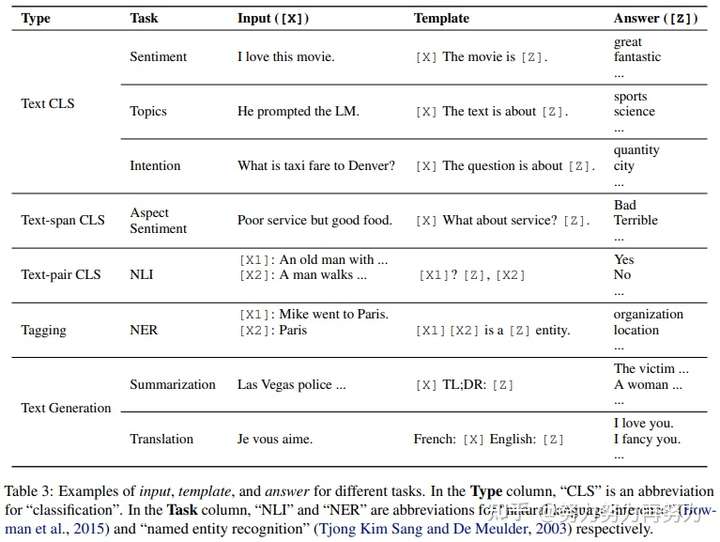
如下图所示,这个任务是让模型来预测一个国家的首都。左边是全token的prompt,文献里称为“离散的prompt”,有的同学一听"离散"就感觉懵了,其实就是一个一个token组成的prompt就叫“离散的prompt”。
右边是token+vector形式的prompt,其实是保留了原token prompt里面的关键信息(capital, Britain),(capital, Britain)是和任务、输出结果最相关的信息,其他不关键的词汇(the, of ,is)留给模型来学习。
如图中所示:
token形式的prompt: “The captital of Britain is [MASK]”
token+vector: “h_0 , h_1, ... h_i, captital, Britain, h_(i+1), ..., h_m [MASK]”

作者公开了代码: https://github.com/THUDM/ P-tuning
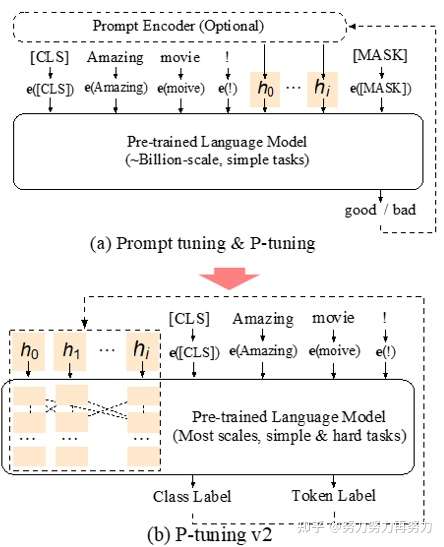
3.2 P-tuning v2——全vector prompt
全vector prompt来了!!!全vecotor可以直接拼接在预训练模型的layer里面,而且这个模型可以做序列tagging任务(给输入序列中每个token打标签)!
论文在这里啦 https://arxiv.org/pdf/2110.07602.pdf
作者也公开了代码,https://github.com/THUDM/P-tuning-v2
更多信息可以看智源组织的各位大佬关于Prompt技术的分享,可以看B站上的这个视频~~~
3.3 PPT——预训练prompt
(哈哈,这个PPT不是你想的PPT哟!)
以上Prompt采用vector形式之后,在训练集比较大(full-data)的时候效果是好的,但是在few-shot(训练集很小)场景下就不好了,因为数据量小不好学嘛。那怎么办呢?既然NLP任务都有预训练模型,那么prompt是否也可以先进行预训练再微调呢?事实证明世上无难事,只要肯放弃(啊不对,只怕有心人),于是乎PPT(Pre-trained Prompt Tuning)模型就诞生了,这个模型就是拿大量无标签语料对Prompt先做个预训练,再在下游任务上做微调。这里不详细讲了,感兴趣的可以去看PPT论文[4]。
4. 关键要点
- prompt设计:可以手动设计模板,也可以自动学习prompt,这里可填坑的地方比较多
- 预训练模型的选择:选择跟任务贴近的预训练模型即可
- 预测结果到label的映射:如何设计映射函数,这里可填坑的地方也比较多
- 训练策略:根据prompt是否有参数,预训练模型参数要不要调,可以组合出各种训练模式,根据标注数据样本量,选择zero-shot, few-shot还是full-data。比如few-shot场景,训练数据不多,如果prompt有参数,可以固定住预训练模型的参数,只调prompt的参数,毕竟prompt参数量少嘛,可以避免过拟合。
5. 代码实现
清华推出了prompt-tuning工具包,每个 class 都继承了 torch 的类或者 huggingface 的类,可以方便地部署自己的任务, 详细请看github项目代码
也可以看一下
同学写的代码哟~~~王斐:Prompt在中文分类few-shot场景中的尝试 ,里面有数据集构建、模板构建、训练测试一套完整代码!

工具包里PromptModel类包含PLM(预训练模型), Template(prompt模板), Verbalizer(输出和label的映射)。
具体的流程github上已经写的很清楚了,主要包含以下几个步骤:
step1. 定义任务
根据你的任务和数据来定义classes 和 InputExample。
以情感分类任务为例,classes包含2个label:"negative"和"positive"
from openprompt.data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]step2. 定义预训练语言模型
根据具体任务选择合适的预训练语言模型,这里采用的预训练模型是bert,因为根据prompt的设计,是想让模型输出[mask]位置的词语,属于填空问题。
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")step3. 定义prompt模板
这个例子是手动设计模板,模板放在ManualTemplate里面,text = '{"placeholder":"texta"} It was {"mask"}', 其中text_a就是InputExample里面的输入text_a,It was {"mask"} 就是prompt。
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)step4. 定义输出-label映射
在情感分类里面,[Mask]位置的输出是一个单词,我们要把这些单词映射成"positive","negative"标签,这个过程称为"Verbalizer",比如"bad"属于"negative", "good", "wonderful", "great"属于"positive"。
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)step5. 组合构建为PromptModel类
将前面几步构建的模板(promptTemplate)、预训练模型(plm)、输出映射(promptVerbalizer)组成promptModel
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)step6. 定义dataloader
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
step7. 开始训练、测试
# making zero-shot inference using pretrained MLM with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim = -1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'参考资料
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- GPT Understands, Too
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- PPT: Pre-trained Prompt Tuning for Few-shot Learning
- 机器之心:Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢