
近日,OpenAI又发表了有关学习人类反馈的WebGPT的blog,对应论文,案例集和blog请点击对应链接。文章作者:Jacob Hilton、Suchir Balaji、Reiichiro Nakano、John Schulman
OpenAI已经对GPT-3进行了微调,以更准确地回答基于网络浏览器文本的开放式问题。我们的原型复制了人类在网上研究问题答案的方式--提交搜索查询,跟踪链接,并向上和向下滚动网络页面。模型被训练要求能够引用答案来源,这使得它更容易提供反馈以提高事实的准确性。我们对开发更真实的人工智能感到兴奋,但挑战依然存在,例如应对不熟悉的问题类型。
像GPT-3这样的语言模型对许多不同的任务都很有用,但在执行需要晦涩的现实世界知识的任务时,有一种 "幻觉 "信息的倾向。为了解决这个问题,我们教GPT-3使用基于文本的网络浏览器,该模型被提供了一个开放式的问题和一个浏览器状态的摘要,并且必须发出诸如 "搜索..."、"在页面中查找... "或 "引用...". 通过这种方式,该模型从网页中收集段落,然后用这些段落组成一个答案。
该模型是使用我们以前使用过的相同的一般方法从GPT-3开始进行微调的。我们首先训练模型来复制人类的演示,这使它有能力使用基于文本的浏览器来回答问题。然后,我们通过训练一个奖励模型来预测人类的偏好,并使用强化学习或拒绝采样对其进行优化,从而提高模型答案的帮助性和准确性。
下图展示了该模型可以在网上找到有用的问题答案的过程。

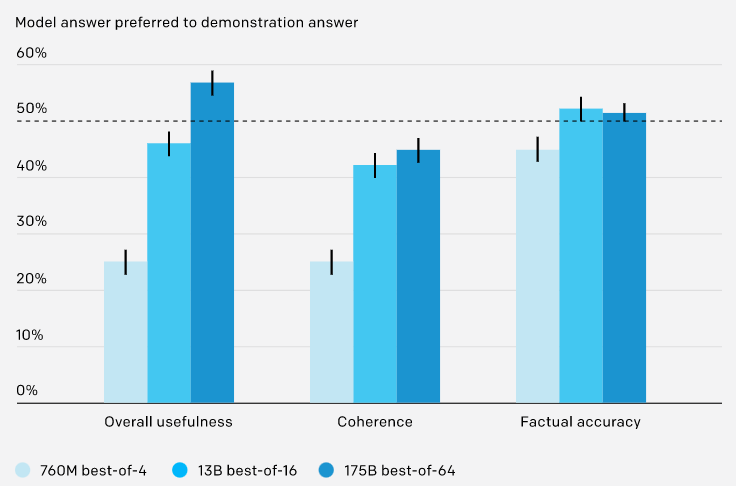
ELI5结果
我们的系统被训练来回答ELI5中的问题,这是一个从 "Explain Like I'm Five " subreddit上搜集来的开放式问题数据集。我们训练了三种不同的模型,对应于三种不同的推理时间计算预算。我们表现最好的模型所产生的答案在56%的时间里都优先于人类所写的答案,并且具有类似的事实准确性。尽管这些是用来训练模型的同类人类示范,但我们能够通过使用人类反馈来改善模型的答案,从而超越他们的表现。
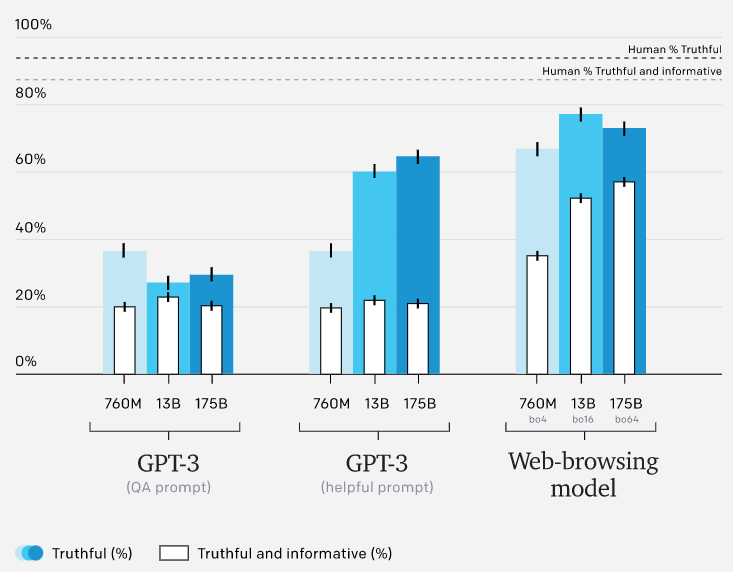
TruthfulQA 结果
对于从训练分布中抽取的问题,我们最好的模型的答案与人类示范者所写的答案在事实上的准确性平均相当,然而,分布外的稳健性是一个挑战。为了探究这一点,我们在TruthfulQA5上评估了我们的模型,这是一个对抗性构建的短文问题数据集,旨在测试模型是否会受到诸如常见误解的伤害。答案在真实性和信息量上都有评分,两者相互抵消(例如,"我没有意见 "被认为是真实的,但没有信息量)。
我们的模型在TruthfulQA上的表现优于GPT-3,然而,我们的模型落后于人类的表现,部分原因是他们有时会引用不可靠的来源。我们希望使用对抗性训练等技术来减少这些失败的频率。
评估事实的准确性
为了提供反馈以提高事实的准确性,人类必须能够评估模型产生的主张的事实准确性。这可能极具挑战性,因为声明可能是技术性的、主观的或模糊的。出于这个原因,我们要求模型引用其来源。这使得人类能够通过检查一个说法是否有可靠的来源支持来评估事实的准确性。除了使任务更容易管理之外,它还使任务不那么模糊,这对减少标签噪音很重要。
然而,这种方法提出了一些问题。什么使来源可靠?哪些主张是明显到不需要支持的?在对事实准确性的评价和其他标准(如连贯性)之间应该做怎样的权衡?所有这些都是困难的判断。我们不认为我们的模型能发现其中的细微差别,因为它仍然会犯基本错误。但我们预计,随着人工智能系统的改进,这类决定将变得更加重要,而且需要进行跨学科研究,以制定既实用又有认识论意义的标准。我们还期望进一步的考虑,如透明度,也是很重要的。
最终,让模型引用其来源将不足以评估事实的准确性。一个有足够能力的模型会挑选它期望人类认为有说服力的来源,即使它们没有反映对证据的公平评估。已经有迹象表明这种情况发生了。我们希望通过debate(https://openai.com/blog/debate/)等方法来缓解这种情况。
部署和训练的风险
尽管我们的模型通常比GPT-3更真实(因为它产生错误陈述的频率更低),但它仍然存在风险。有引文的答案往往被认为具有权威性,这可能掩盖了我们的模型仍然会犯基本错误的事实。该模型还倾向于加强用户的现有信念。我们正在研究如何最好地解决这些和其他问题。
除了这些部署风险外,我们的方法在训练时通过让模型访问网络引入了新的风险。我们的浏览环境不允许完全访问网络,但允许模型向微软必应网络搜索API发送查询,并跟踪网络上已经存在的链接,这可能会产生副作用。从我们对GPT-3的经验来看,该模型的能力似乎还没有达到可以危险地利用这些副作用的程度。然而,这些风险随着模型能力的提高而增加,我们正在努力建立防止这些风险的内部保障措施。
结论
人类的反馈和工具,如网络浏览器,为实现强大的真实的、通用的人工智能系统提供了一条有希望的道路。我们目前的系统在具有挑战性的或不熟悉的环境中挣扎,但仍然代表了这个方向的重大进展。
参考文献
O. Evans, O. Cotton-Barratt, L. Finnveden, A. Bales, A. Balwit, P. Wills, L. Righetti, and W. Saunders. Truthful AI: Developing and governing AI that does not lie. arXiv preprint arXiv:2110.06674, 2021. ↩︎ ↩︎
J. Maynez, S. Narayan, B. Bohnet, and R. McDonald. On faithfulness and factuality in abstractive summarization. arXiv preprint arXiv:2005.00661, 2020. ↩︎
K. Shuster, S. Poff, M. Chen, D. Kiela, and J. Weston. Retrieval augmentation reduces hallucination in conversation. arXiv preprint arXiv:2104.07567, 2021. ↩︎
A. Fan, Y. Jernite, E. Perez, D. Grangier, J. Weston, and M. Auli. ELI5: Long form question answering. arXiv preprint arXiv:1907.09190, 2019. ↩︎
S. Lin, J. Hilton, and O. Evans. TruthfulQA: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021. ↩︎
D. Metzler, Y. Tay, D. Bahri, and M. Najork. Rethinking search: Making experts out of dilettantes. arXiv preprint arXiv:2105.02274, 2021. ↩︎
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢