
本文分享论文『SWIN BERT: End-to-End Transformers with Sparse Attention for Video Captioning』,微软提出第一个端到端的Video Captioning方法《SWIN BERT》,涨点显著!

论文链接:
https://arxiv.org/abs/2111.13196
视频字幕的标准方法是定义一个字幕生成模型,以从大量提取的密集视频特征中学习。这些特征提取器通常对以固定帧率采样的视频帧进行操作,并且通常对图像/视频理解任务进行预训练,而没有适应视频字幕数据。在这项工作中,作者提出了SwinBERT ,这是一种基于端到端Transformer的视频字幕模型,该模型直接将视频帧patch作为输入,并输出自然语言描述。
本文的方法不是利用多个2D/3D特征提取器,而是采用视频Transformer来编码时空表示,该表示可以适应可变长度的视频输入,而无需针对不同帧率进行专门设计。基于这个模型结构,作者证明了视频字幕可以从更密集的采样视频帧中获得显著的增益。此外,为了避免连续视频帧中固有的冗余,作者提出自适应学习稀疏注意掩码,并通过更好的远程视频序列建模来优化任务特定性能的改进。通过对5个视频字幕数据集的广泛实验,作者表明S WIN BERT比以前的方法实现了全面的性能改进,通常提升幅度很大。
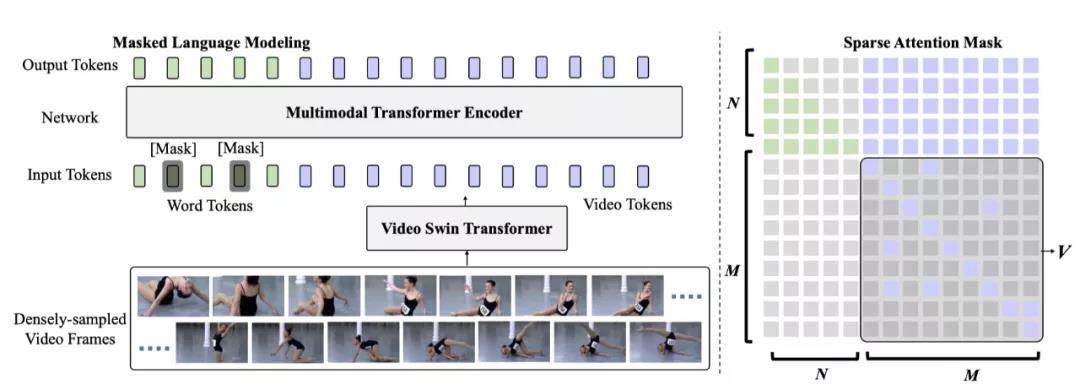
上图展示了本文所提出的模型。SwinBERT将一系列原始视频帧作为输入,然后输出描述输入视频的自然语言描述。SwinBERT由两个模块组成: 视频Swin Transformer (VidSwin) 和多模态Transformer编码器。首先,作者利用VidSwin从原始视频帧中提取时空视频表示。然后,本文的多模态Transformer编码器将视频表示作为输入,并通过序列到序列 (seq2seq) 生成输出自然语言句子。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢