标题:Meta、Google、Outreach等|XLS-R: SELF-SUPERVISED CROSS-LINGUAL SPEECH REPRESENTATION LEARNING AT SCALE(XLS-R:自监督跨语言语音大规模表示学习)
作者:Arun Babu, Changhan Wang, Michael Auli等
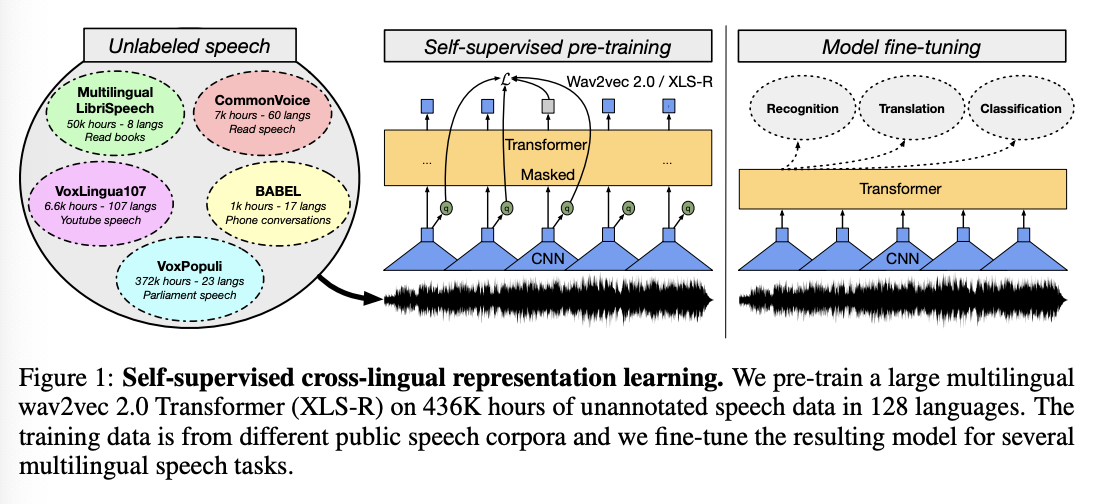
简介:本文介绍了基于wav2vec 2.0的大规模跨语言语音表示学习。作者基于近50万小时的128种语言的公开语音音频,训练最多20亿个参数模型,公开数据比已知最大的先前工作多出一个数量级。作者的评估涵盖了广泛的任务、领域、数据机制和语言,无论是高和低资源。在CoVoST-2语音翻译基准上,作者改进了在21个翻译方向上平均7.4BLEU得分。对于语音识别,XLS-R 改进了在 BABEL、MLS、CommonVoice 以及 VoxPopuli 上最著名的先验工作,降低平均相对14-34%错误率。 XLS-R还设置了VoxLingua107语言识别的最新技术。在足够大的模型尺寸下,跨语言预训练的表现与仅英语的预训练一样好,将英语演讲翻译成其他语言,这种环境有利于单语预训练。
代码下载:https://www.github.com/pytorch/fairseq/tree/master/examples/wav2vec/xlsr
论文下载:https://arxiv.org/pdf/2111.09296v3.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢